

Image segmentation has become a popular technology, with different fine-tuned models available for various purposes. The model labels every pixel in an image by streaming every region of the input image; this concept makes the idea of semantic segmentation into reality and application.
This Face parsing model is a semantic segmentation technology fine-tuned from Nvidia’s mit-b5 and Celebmask HQ. Its intended use is for face parsing, which labels different areas in an image, especially the facial features.
It can also detect objects and label them with pre-trained data. So, you can get labels for everything from the background to the eyes, nose, skin, eyebrows, clothes, hat, neck, hair, and other features.
Learning Objective
- Understand the concept of face parsing as a semantic segmentation model.
- Highlights some key points about face parsing.
- Learn how to run the face parsing model.
- Get Insight into the real-life applications of this model.
This article was published as a part of the Data Science Blogathon.
What is Face Parsing?
Face parsing is a computer vision technology that completes tasks that help in the face analysis of an input image. This process occurs by pixel-segmenting the image’s facial parts and other visible areas. With this image segmentation task, users can further modify, analyze, and utilize the applications of this model in various ways.
Understanding the model architecture is a key concept of how this model works. Although this process has a lot of pre-trained data, this model’s vision transformer architecture is more efficient.
Model Architecture of Face Parsing Model
This model uses a transformer-based architecture for semantic segmentation, which provides a good foundation for how other similar models like Segformer are built. In addition to integrating the transformer system, it also focuses on a lightweight decoding mechanism when processing an image.
Looking at the key component of how this mechanism works, you see it consists of a transformer encoder, an MLP decoder, and no positioning embeddings. These are vital attributes of the working system of transformer models in image segmentation.
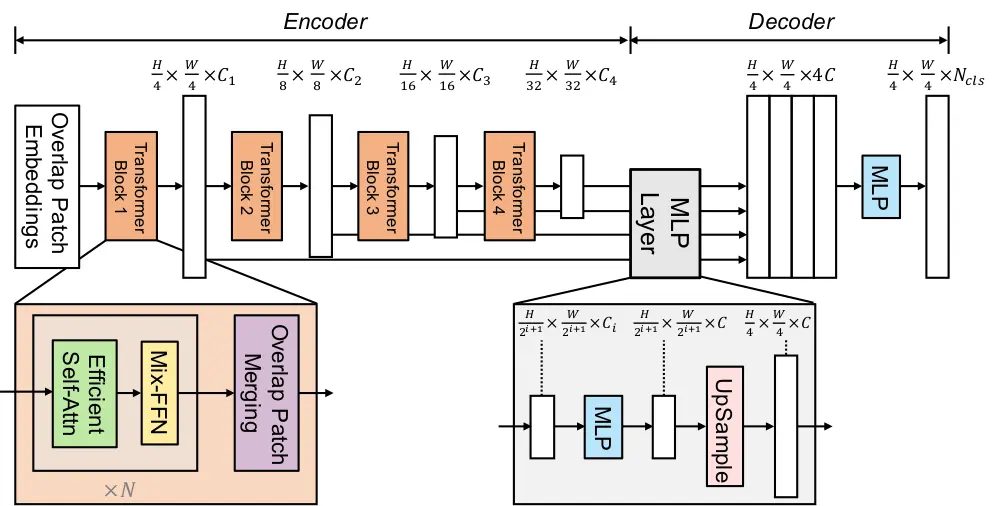
The transformer encoder is an essential part of the mechanism, helping to extract multi-scale features from the input image. Thus, you can capture the images with information on different spatial scales to improve the model’s efficiency.
The lightweight decoder is another vital part of this model’s architecture. It is based on a multi-layer perception decoder, enabling it to compile information from different layers of the transformer encoder. This model can do this by utilizing local and global attention mechanisms; local attention helps to recognize facial features, while global attention ensures good coverage of the facial structure.
This mechanism balances the model’s performance and efficiency. Thus, this architecture enables minimizing resources without affecting the output.
No-position encoding is another essential part of the face parsing architecture, which has become a staple in many computer vision and transformer models. This feature is tailored to avoid image resolution problems, even for images beyond a boundary. So, it maintains efficiency regardless of positional codes.
Overall, the model’s design performs well on standard face segmentation benchmarks. It is effective and can generalize across diverse face images, making it a robust choice for tasks like facial recognition, avatar generation, or AR filters. The model maintains sharp boundaries between facial regions, an essential requirement for accurate face parsing.
How to Run the Face Parsing Model
This section outlines the steps for running this model’s code with resources from the hugging face library. The result would show the labels of each facial feature that it can recognize. You can run this model using the inference API and libraries. So, let’s explore these methods.
Running Inference on the Face Parsing Using Hugging Face
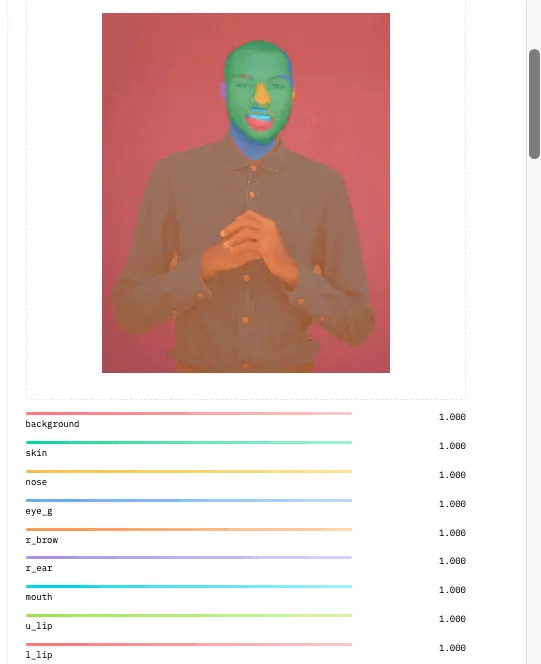
You can use the inference API available on hugging face to complete the face parsing tasks. The model’s inference API tool takes an image as input, and the face parsing labels the parts of the face on the image using colors.
import requests
API_URL = "https://api-inference.huggingface.co/models/jonathandinu/face-parsing"
headers = {"Authorization": "Bearer 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"}
def query(filename):
with open(filename, "rb") as f:
data = f.read()
response = requests.post(API_URL, headers=headers, data=data)
return response.json()
output = query("/content/IMG_20221108_073555.jpg")The code above starts with the request library to handle HTTPS requests and communicate with the API over web platforms. So, using hugging face as the API, you can get authorization using the token that can be created for free on the platform. While the URL specifies the endpoint of the model, the token is used for authentication when making requests to the hugging face API.
The rest of the code sends an image file to the API and gets the results. The query function is called with a file that shows the location of the image. The function sends the image to the API and stores the response (JSON format) in the variable output.
outputNext, you enter your ‘output.’ variable to show the result of the inference.

Importing the Essential Libraries
This code imports the necessary libraries for the image segmentation task, using Segformer as the base model. It also brings an image processor from the Transformers library to process and run the Segformer model. Then, it imports PIL to handle image loading and Matplotlib to visualize the segmentation results. Lastly, requests are imported to fetch images from URLs.
import torch
from torch import nn
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
from PIL import Image
import matplotlib.pyplot as plt
import requestsEngaging Hardware– GPU/CPU/
device = (
"cuda"
# Device for NVIDIA or AMD GPUs
if torch.cuda.is_available()
else "mps"
# Device for Apple Silicon (Metal Performance Shaders)
if torch.backends.mps.is_available()
else "cpu"
)
This code engages the available hardware of the local device suitable for running this model. As shown in the code, it assigns ‘cuda’ for NVIDIA or AMD GPUs and mps for Apple silicon devices. By default, this model just utilizes the CPU without other available hardware.
Loading the Processors
The code below loads the segformer image processor and semantic segmentation model, pre-trained on ‘jonathandinu/face-parsing’ with datasets for face parsing tasks.
image_processor = SegformerImageProcessor.from_pretrained("jonathandinu/face-parsing")
model = SegformerForSemanticSegmentation.from_pretrained("jonathandinu/face-parsing")
model.to(device)The next step involves fetching the image for the image segmentation task. You can do this by uploading the file or loading the URL of the image as shown in the image below;
url = "https://images.unsplash.com/photo-1539571696357-5a69c17a67c6"
image = Image.open(requests.get(url, stream=True).raw)
This code processes an image using the `image_processor,` converting it into a PyTorch tensor and moving it to the specified device (GPU, MPS, or CPU).
inputs = image_processor(images=image, return_tensors="pt").to(device)
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, ~height/4, ~width/4)The processed tensor is fed into the Segformer model to generate segmentation outputs. The logits are extracted from the model’s output, representing the raw scores for each pixel across different labels, with dimensions scaled down by 4 for height and width.
Output
To get the output, there are a few lines of code to help you display the image results. Firstly, you resize the output to ensure that it matches the dimensions of the image input. This is done by using linear interpolation to get a value to estimate the points of the image size.
# resize output to match input image dimensions
upsampled_logits = nn.functional.interpolate(logits,
size=image.size[::-1], # H x W
mode="bilinear",
align_corners=False)
Secondly, you need to run the label masks to help the output value in the class dimensions.
# get label masks
labels = upsampled_logits.argmax(dim=1)[0]
Finally, you can visualize the image using the ‘metaplotlib’ library.
# move to CPU to visualize in matplotlib
labels_viz = labels.cpu().numpy()
plt.imshow(labels_viz)
plt.show()
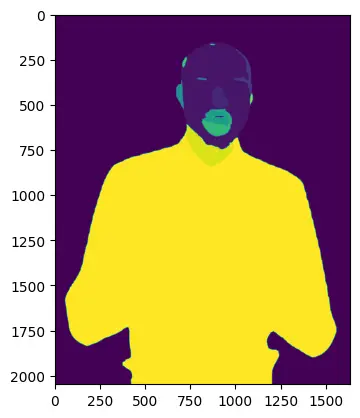
The image brings the labels of the facial features as shown below;
Real-Life Application of Face Parsing Model
This model has various applications across different industries with many similar fine-tuned models already in use. Here are some of the popular applications of face-parsing technology;
- Security: This model has facial recognition capabilities, which allow it to identify people through facial features. It can also help identify a list of people allowed into an event or private gathering while blocking unrecognized faces.
- Social media: Image segmentation has become rampant in the social media space, and this model also brings value to this industry. The model can modify skin tones and other facial features, which can be used to create beauty effects in photos, videos, and online meetings.
- Entertainment: Face parsing has a huge influence on the entertainment industry. Various parsing attributes can help producers change the colors and tones in different positions of an image. You can analyze the image, add ornaments, and modify some parts of an image or video.
Conclusion
The face parsing model is a powerful semantic segmentation tool designed to label and analyze facial features in images and videos accurately. This model uses a transformer-based architecture to efficiently extract multi-scale features while ensuring performance through a lightweight decoding mechanism and the absence of positional encodings.
Its versatility enables various real-world applications, from enhancing security through facial recognition to providing advanced image editing features in social media and entertainment.
Key Takeaways
- Transformer-Based Architecture: This mechanism plays an essential role in the efficiency and performance of this model. Also, this system’s no positional encoding attribute avoids image resolution problems.
- Versatile Applications: This model can be utilized in different industries; security, entertainment, and social media spaces can find valuable uses of face parsing technology.
- Semantic Segmentation: By accurately segmenting every pixel related to facial features, the model facilitates detailed analysis and manipulation of images, providing users with valuable insights and capabilities in face analysis.
Resources
Frequently Asked Questions
A. Face parsing is a computer vision technology that segments an image into different facial features, labeling each area, such as the eyes, nose, mouth, and skin.
A. The model processes input images through a transformer-based architecture that captures multi-scale features. This is followed by a lightweight decoder that aggregates information to produce accurate segmentation results.
A. Key applications include security (facial recognition), social media (photo and video enhancements), and entertainment (image and video editing).
A. The transformer architecture allows for efficient image processing, better handling of varying image resolutions, and improved segmentation accuracy without needing positional encoding.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.