

In our fast-paced digital age, accessing the most current information quickly is more important than ever. Traditional sources often fall short, either because they’re outdated or simply unavailable when we need them the most. This is where the concept of a real-time, web-enhanced Agentic RAG application steps in, offering a groundbreaking solution. By harnessing the capabilities of LangChain and LLMs for language understanding and Tavily for real-time web data integration, developers can create applications that go beyond the limitations of static databases.
This innovative approach enables the application to scour the web for the latest information, ensuring that users receive the most relevant and current answers to their queries. It’s an intelligent assistant that doesn’t just respond with pre-loaded information but actively seeks out and incorporates new data in real time. This article aims to guide you through the development of such an application, addressing potential challenges like maintaining accuracy and ensuring speedy responses. The goal is to democratize access to information, making it as up-to-date and accessible as possible, thereby removing the barriers to the wealth of knowledge available on the internet. Join us in exploring how to build an AI-powered, web-enhanced Agentic RAG Application that puts the world’s information at your fingertips.

Learning Objectives
- Gain a comprehensive understanding of building a state-of-the-art, real-time Agentic Retrieval-Augmented Generation (RAG) application.
- Learn to integrate advanced technologies seamlessly into your application.
This article was published as a part of the Data Science Blogathon.
What is Agentic RAG and How Does it Work?
Agentic Retrieval-Augmented Generation (RAG) is an advanced framework that coordinates multiple tools to tackle complex tasks by integrating information retrieval with language generation. This system enhances traditional RAG by utilizing specialized tools, each focused on distinct subtasks, to produce more accurate and contextually relevant outputs. The process begins by decomposing a complex problem into smaller, manageable subtasks, with each tool handling a specific aspect of the task. These tools interact through a shared memory or message-passing mechanism, allowing them to build upon each other’s outputs and refine the overall response.
Certain tools are equipped with retrieval capabilities, enabling access to external data sources such as databases or the Internet. This ensures that the generated content is grounded in accurate and up-to-date information. After processing their respective tasks, the tools combine their findings to generate a coherent and comprehensive final output that addresses the original query or task.
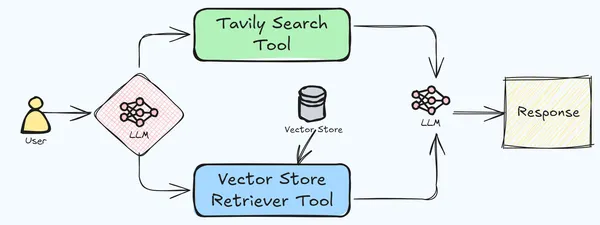
This approach offers several benefits, including specialization, where each tool excels in a particular area, leading to more precise handling of complex tasks; scalability, due to the modular nature of the system, allowing for easy adaptation to various applications and domains; and reduced hallucination, as incorporating multiple tools with retrieval capabilities enables cross-verification of information, minimizing the risk of generating incorrect or fabricated content. In our current application, we will use the Tavily web search and vector store retrieval tools to create an advanced RAG pipeline.
Skills Necessary to Implement
The knowledge and skills necessary to implement this solution effectively.
- Tavily Search API: From their docs, Tavily Search API is a search engine optimized for LLMs, aimed at efficient, quick and persistent search results.’ Using the Tavily API, we can easily integrate real-time web search into LLM-based applications. LangChain has integration of Tavily API for real-time web search, which searches for relevant information from the web based on the user’s query. Tavily API has the capability to fetch relevant information from multiple sources, which includes the URL, relevant images and the content, all in a structured JSON format. This fetched information is then used as a context for LLM to answer the user’s query. We will be building an agent utilizing the Tavily integration of LangChain that will be used by the pipeline to answer queries when the LLM is not able to answer from the provided document.
- OpenAI GPT-4 Turbo: We will be using OpenAI’s GPT 4 Turbo model for this experiment, but you can use any model for this pipeline, including local models. Please don’t use OpenAI’s GPT 4o model, as it is seen to not perform well on agentic applications.
- Apple’s 2023 10-K Document: We will be using the 10K Annual reports document for this experiment, but you can use any document of choice.
- Deeplake Vector Store: For this application, we will be using the Deeplake vector store. It’s fast and lightweight, which helps maintain the latency of the application.
- Simple SQL Chat Memory (optional): Additionally, we will implement a basic SQL-based chat memory system for maintaining context and continuity across interactive chat sessions. This is optional but keeping it in the application enhances user experience.
Implementation of Agentic RAG Application
Now we’ll walk through the creation of this simple, yet powerful Retrieval-Augmented Generation (RAG) system designed to answer user queries with high accuracy and relevance. The code outlined below demonstrates how to integrate these components into a cohesive application capable of retrieving information both from a specific document and the vast resources of the web. Let’s dive into the specifics of the implementation, examining how each part of the code contributes to the overall functionality of the system.
Creating Environment
First, create an environment using the below-mentioned packages-
#install dependencies
deeplake==3.9.27
ipykernel==6.29.5
ipython==8.29.0
jupyter_client==8.6.3
jupyter_core==5.7.2
langchain==0.3.7
langchain-community==0.3.5
langchain-core==0.3.15
langchain-experimental==0.3.3
langchain-openai
langchain-text-splitters==0.3.2
numpy==1.26.4
openai==1.54.4
pandas==2.2.3
pillow==10.4.0
PyMuPDF==1.24.13
tavily-python==0.5.0
tiktoken==0.8.0Environment Setup and Initial Configurations: First, the necessary libraries are imported. This sets up the foundation for the application to interact with various services and functionalities.
Initial Configurations
import os
from langchain_core.prompts import (
ChatPromptTemplate,
)
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain.tools.retriever import create_retriever_tool
from langchain.tools.tavily_search import TavilySearchResults
from langchain.vectorstores.deeplake import DeepLake
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.memory import ConversationBufferWindowMemory, SQLChatMessageHistoryTavily Search Tool Configuration
Tavily Search Tool Configuration: Next, the TavilySearchResults tool is configured for web searches, setting parameters like max_results and search_depth. First, we export the Tavily API key as os environment. You can get your own Tavily API key from here, by generating a new one.
os.environ["TAVILY_API_KEY"] = "tavily_api_key"
search_tool = TavilySearchResults(
name="tavily_search_engine",
description="A search engine optimized for retrieving information from web based on user query.",
max_results=5,
search_depth="advanced",
include_answer=True,
include_raw_content=True,
include_images=True,
verbose=False,
)Chat OpenAI Configuration
Chat OpenAI Configuration: The Chat OpenAI model is configured with the GPT-4 model details and API keys. Note that any Chat model can be used for this use-case. Check the LangChain documentation for the model you wish to use and modify the code accordingly.
llm = ChatOpenAI(
model="gpt-4",
temperature=0.3,
api_key="openai_api_key",
)Defining the Prompt Template
Defining the Prompt Template: A ChatPromptTemplate is defined to guide the chatbot’s interaction with users, emphasizing the use of document context and web search.
prompt = ChatPromptTemplate([
("system",
f"""You are a helpful chatbot. You need to answer the user's queries in
detail from the document context. You have access to two tools:
deeplake_vectorstore_retriever and tavily_search_engine.
Always use the deeplake_vectorstore_retriever tool first to retrieve
the context and answer the question. If the context does not contain relevant
answer for the user's query, use the tavily_search_engine to fetch web search
results to answer them. NEVER give an incomplete answer. Always try your best
to find answer through web search if answer is not found from context."""),
("human", "{user_input}"),
("placeholder", "{messages}"),
("placeholder", "{agent_scratchpad}"),
])Document Pre-processing and Ingestion
Document Pre-processing and Ingestion: The document is loaded, split into chunks, and these chunks are processed to create embeddings, which are then stored in a DeepLake vector store.
data = "Apple 10k 2023.pdf"
loader = PyMuPDFLoader(file_path=data)
text_splitter = CharacterTextSplitter(separator="\n", chunk_size=1000, chunk_overlap=200)
docs = loader.load_and_split(text_splitter=text_splitter)
embeddings = OpenAIEmbeddings(api_key="openai_api_key",)
vectorstore = DeepLake(dataset_path="dataset", embedding=embeddings,)
_ = vectorstore.add_documents(documents=docs)Creating the Retrieval tool
Creating the Retrieval tool: A retrieval tool is created from the vector store to facilitate document search.
retriever_tool = create_retriever_tool(
retriever=vectorstore.as_retriever(
search_type="similarity",
search_kwargs={
"k": 6,
"fetch_k": 12,
},
),
name="deeplake_vectorstore_retriever",
description="Searches and returns contents from uploaded Apple SEC document based on user query.",
)
tools = [
retriever_tool,
search_tool,
]Implementing a simple chat history/memory (Optional): An SQL-based chat memory is configured for maintaining the context. A SQLite database will be created and the chat conversations will be stored in that.
history = SQLChatMessageHistory(
session_id="ghdcfhdxgfx",
connection_string="sqlite:///chat_history.db",
table_name="message_store",
session_id_field_name="session_id",
)
memory = ConversationBufferWindowMemory(chat_memory=history)Initializing the Agent and Agent Executor
Initializing the Agent and Agent Executor: An agent is created and executed to process user queries and generate responses based on the configured tools and memory.
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
tools=tools,
agent=agent,
verbose=False,
max_iterations=8,
early_stopping_method="force",
memory=memory,
)Testing the pipeline on a few samples: With this, we have our RAG with Real-time search pipeline is ready. Let’s test the application with some queries.
result = agent_executor.invoke({
"user_input": "What is the fiscal year highlights of Apple inc. for 2nd quarter of 2024?",
},)
print(result["output"])Output
The document does not contain specific information about the fiscal year
highlights of Apple Inc. for the 2nd quarter of 2024. The latest information
includes:Total Net Sales and Net Income: Apple's total net sales were $383.3 billion,
and net income was $97.6 billion during 2023.Sales Performance: There was a 3% decrease in total net sales compared to
2022, amounting to an $11.0 billion reduction. This decrease was attributed
to currency exchange headwinds and weaker consumer demand.Product Announcements: Significant product announcements during fiscal year
2023 included:First Quarter: iPad and iPad Pro, Next-generation Apple TV 4K, and MLS Season
Pass (a Major League Soccer subscription streaming service).
Second Quarter: MacBook Pro 14", MacBook Pro 16", and Mac mini; Second-
generation HomePod.
Third Quarter: MacBook Air 15", Mac Studio and Mac Pro; Apple Vision Pro™
(the company's first spatial computer featuring its new visionOS).
Fourth Quarter: iPhone 15 series (iPhone 15, iPhone 15 Plus, iPhone 15 Pro,
and iPhone 15 Pro Max); Apple Watch Series 9 and Apple Watch Ultra 2.
Share Repurchase Program: In May 2024, Apple announced a new share repurchase
program of up to $90 billion and raised its quarterly dividend.For the specific details regarding the 2nd quarter of 2024, it would be
necessary to consult Apple's official publications or financial reports.
The query that we asked was related to 2024, for which the model replied that the context has no information for 2024 highlights and gives the details for 2023, which it gets from the vector store. Next, let’s try asking the same question but for Nvidia.
result = agent_executor.invoke({
"user_input": "What is the fiscal year highlights of Nvidia inc. for 2nd quarter of 2024?",
},)
print(result["output"])Output
The text from the image is:For the 2nd quarter of the fiscal year 2024, Nvidia Inc. reported exceptional
growth, particularly driven by its Data Center segment. Here are the
highlights:Total Revenues: Nvidia's total revenue saw a significant increase, up 101%
year-over-year (YOY) to $13.51 billion, which was above the outlook.Data Center Revenue: The Data Center segment experienced a remarkable growth
of 171% YOY, reaching $10.32 billion. This growth underscores the strong
demand for AI-related computing solutions.Gaming Revenue: The Gaming segment also saw growth, up 22% YOY to $2.49
billion.Record Data Center Revenue: Nvidia achieved a record in Data Center revenue,
highlighting the strong demand for its products and services.These results reflect Nvidia's strong position in the market, particularly in
areas related to accelerated computing and AI platforms. The company
continues to benefit from trends in artificial intelligence and machine
learning.For more detailed information, you can refer to Nvidia's official press
release regarding their financial results for the second quarter of fiscal
year 2024.
Also read: RAG vs Agentic RAG: A Comprehensive Guide
Key Takeaways
- Integration of Advanced Technologies: Combines tools like LangChain, Azure OpenAI, Tavily Search API, and DeepLake vector stores to create a robust system for information retrieval and NLP.
- Retrieval-Augmented Generation (RAG): Blends real-time web search, document retrieval, and conversational AI to deliver accurate and context-aware responses.
- Efficient Document Management: Uses DeepLake vector stores for quick retrieval of relevant document sections, optimizing large document handling.
- Azure OpenAI Language Modeling: Leverages GPT-4 for coherent, human-like, and contextually appropriate responses.
- Dynamic Web Search: Tavily Search API enriches responses with real-time web information for comprehensive answers.
- Context and Memory Management: SQL-based chat memory ensures coherent, context-aware interactions across sessions.
- Flexible, Scalable Architecture: Modular and configurable design supports easy expansion with additional models, information sources, or features.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Conclusion
In this article, we explored the creation of a real-time, Agentic RAG Application using LangChain, Tavily, and OpenAI GPT-4. This powerful integration of technologies enables the application to provide accurate, contextually relevant answers by combining document retrieval, real-time web search, and conversational memory. Our guide presents a flexible and scalable approach, adaptable to various models, data sources, and functionalities. By following these steps, developers can build advanced AI-powered solutions that meet today’s demand for up-to-date and comprehensive information accessibility.
If you are looking for an RAG course online then explore: RAG Systemt Essentials.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
Ans. The primary purpose of Agentic RAG application is to provide accurate, real-time answers by combining document retrieval, real-time web search, and language generation. It leverages specialized tools for subtasks, ensuring precise and contextually relevant responses.
Ans. The Tavily Search API integrates real-time web search into the system, fetching up-to-date, relevant information in a structured JSON format. It provides additional context to queries that cannot be answered by pre-loaded document data alone.
Ans. DeepLake serves as the vector store for storing document embeddings. It allows for efficient retrieval of relevant document chunks based on similarity search, ensuring the application can quickly access and use the required information.
An ace multi-skilled programmer whose major area of work and interest lies in Software Development, Data Science, and Machine Learning. A proactive and detail-oriented individual who loves data storytelling, and is curious and passionate to solve complex value-oriented business problems with Data Science and Machine Learning to deliver robust machine learning pipelines that ensure maximum impact.
In my free time, I focus on creating Data Science and AI/ML content, providing 1:1 mentorships, career guidance and interview preparation tips, with a sole focus on teaching complex topics the easier way, to help people make a successful career transition to Data Science with the right skillset!