

Creating AI agents that can interact with the real world is a great area of research and development. One useful application is building agents capable of searching the web to gather information and complete tasks. This blog post will guide you through the process of creating such an agent using LangChain, a framework for developing LLM-powered applications, and Llama 3.3, a state-of-the-art large language model.
Learning Objectives
- Understand how to build an AI agent using LangChain and Llama 3.3 for web searching tasks.
- Learn how to integrate external knowledge sources like ArXiv and Wikipedia into a web-searching agent.
- Gain hands-on experience setting up the environment and necessary tools to develop an AI-powered web app.
- Explore the role of modularity and error handling in creating reliable AI-driven applications.
- Understand how to use Streamlit for building user interfaces that interact seamlessly with AI agents.
This article was published as a part of the Data Science Blogathon.
What is Llama 3.3?
Llama 3.3 is a 70-billion parameter, instruction-tuned large language model developed by Meta. It is optimized to perform better on text-based tasks, including following instructions, coding, and multilingual processing. In comparison, it outperforms its forerunners, including Llama 3.1 70B and Llama 3.2 90B. It can even compete with larger models, such as Llama 3.1 405B in some areas, while saving costs.
Features of Llama 3.3
- Instruction Tuning: Llama 3.3 is fine-tuned to follow instructions accurately, making it highly effective for tasks that require precision.
- Multilingual Support: The model supports multiple languages, including English, Spanish, French, German, Hindi, Portuguese, Italian, and Thai, enhancing its versatility in diverse linguistic contexts.
- Cost Efficiency: With competitive pricing, Llama 3.3 can be an affordable solution for developers who want high-performance language models without prohibitive costs.
- Accessibility: Its optimized architecture allows it to be deployed on a variety of hardware configurations, including CPUs, making it accessible for a wide range of applications.
What is LangChain?
LangChain is an open-source framework, useful for building applications powered by large language models (LLMs). The suite of tools and abstractions simplifies the integration of LLMs in various applications, enabling developers to create sophisticated AI-driven solutions with ease.
Key Features of LangChain
- Chainable Components: LangChain enables developers to create complex workflows by chaining together different components or tools, facilitating the development of intricate applications.
- Tool Integration: It supports the incorporation of various tools and APIs, enabling the development of agents capable of interacting with external systems easily.
- Memory Management: LangChain provides mechanisms for managing conversational context, allowing agents to maintain state across interactions.
- Extensibility: The framework accommodates custom components and integrations as needed, making it easily extendable.
Core Components of a Web-Searching Agent
Our web-searching agent will consist of the following key components:
- LLM (Llama 3.3): The brain of the agent, responsible for understanding user queries, generating search queries, and processing the results.
- Search Tool: A tool that allows the agent to perform web searches. We’ll use a search engine API for this purpose.
- Prompt Template: A template that structures the input provided to the LLM, ensuring it receives the necessary information in the correct format.
- Agent Executor: The component that orchestrates the interaction between the LLM and the tools, executing the agent’s actions.
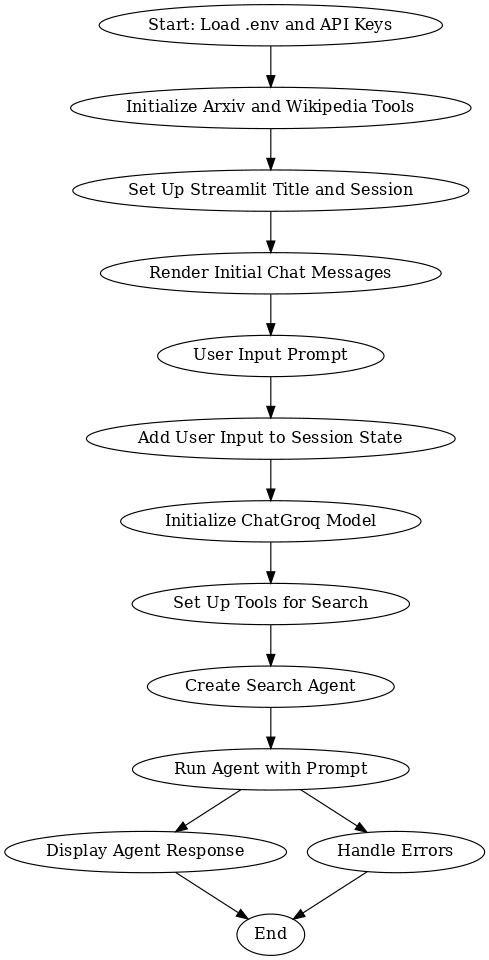
Flow Diagram
This workflow outlines the process of integrating multiple tools and models to create an interactive system using Arxiv, Wikipedia, and ChatGroq, powered by Streamlit. It starts by loading necessary API keys and setting up the required tools. The user is then prompted to input their query, which is stored in the session state. The ChatGroq model processes this input while search tools gather relevant information from Arxiv and Wikipedia. The search agent combines the responses and displays a relevant answer to the user.
The process ensures seamless user interaction by initializing the tools, managing user input, and providing accurate responses. In case of errors, the system handles them gracefully, ensuring a smooth experience. Overall, this workflow allows the user to efficiently receive responses based on real-time data, leveraging powerful search and AI models for a rich and informative conversation.
Setting Up the Base
Setting up the base is the first crucial step in preparing your environment for efficient processing and interaction with the tools and models required for the task.
Environment Setup
Environment setup involves configuring the necessary tools, API keys, and settings to ensure a smooth workflow for the project.
# Create a Environment
python -m venv env
# Activate it on Windows
.\env\Scripts\activate
# Activate in MacOS/Linux
source env/bin/activateInstall the Requirements.txt
pip install -r https://raw.githubusercontent.com/Gouravlohar/Search-Agent/refs/heads/master/requirements.txtAPI Key Setup
Make a .env file in your project and visit Groq for API Key.
After getting your API Key paste it in your .env file
GROQ_API_KEY="Your API KEY PASTE HERE"Step1: Importing Necessary Libraries
import streamlit as st
from langchain_groq import ChatGroq
from langchain_community.utilities import ArxivAPIWrapper, WikipediaAPIWrapper
from langchain_community.tools import ArxivQueryRun, WikipediaQueryRun
from langchain.agents import initialize_agent, AgentType
from langchain_community.callbacks.streamlit import StreamlitCallbackHandler # Updated import
import os
from dotenv import load_dotenvImport libraries to build the Webapp, interact with Llama 3.3, query ArXiv and Wikipedia tools, initialize agents, handle callbacks, and manage environment variables.
Step2: Loading Environment Variables
load_dotenv()
api_key = os.getenv("GROQ_API_KEY") - load_dotenv(): Fetch environment variables from .env file in the project directory. This is a secure way to manage sensitive data.
- os.getenv(“GROQ_API_KEY”): Retrieves the GROQ_API_KEY from the environment(.env File), which is necessary to authenticate requests to Groq APIs.
Step3: Setting Up ArXiv and Wikipedia Tools
arxiv_wrapper = ArxivAPIWrapper(top_k_results=1, doc_content_chars_max=200)
arxiv = ArxivQueryRun(api_wrapper=arxiv_wrapper)
api_wrapper = WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=200)
wiki = WikipediaQueryRun(api_wrapper=api_wrapper)- top_k_results=1: Specifies that only the top result should be retrieved.
- doc_content_chars_max=200: It will limits the length of the retrieved document content to 200 characters for summaries.
- ArxivQueryRun and WikipediaQueryRun: Connect the wrappers to their respective querying mechanisms, enabling the agent to execute searches and retrieve results efficiently.
Step4: Setting the App Title
st.title("🔎Search Web with Llama 3.3")Set a user-friendly title for the web app to indicate its purpose.
Step5: Initializing Session State
if "messages" not in st.session_state:
st.session_state["messages"] = [
{"role": "assistant", "content": "Hi, I can search the web. How can I help you?"}
]Set up a session state to store messages and ensure the chat history persists throughout the user session.
Step6: Displaying Chat Messages
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg['content'])- st.chat_message(): It displays messages in the chat interface. The msg[“role”] determines whether the message is from the “user” or the “assistant.”
Step7: Handling User Input
if prompt := st.chat_input(placeholder="Enter Your Question Here"):
st.session_state.messages.append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)- st.chat_input(): Creates an input field for the user to enter their question.
- Adding User Messages: Appends the user’s questions to the session state and displays it in the chat interface.
Step8: Initializing the Language Model
llm = ChatGroq(groq_api_key=api_key, model_name="llama-3.3-70b-versatile", streaming=True)
tools = [arxiv, wiki]- groq_api_key: Uses the API key to authenticate.
- model_name: Specifies the Llama 3.3 model variant to use.
- streaming=True: Enables real-time response generation in the chat window.
- Tools: Includes the ArXiv and Wikipedia querying tools, making them available for the agent to use.
Step9: Initializing the Search Agent
search_agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, handle_parsing_errors=True)Combine both the tools and the language model to create a zero-shot agent capable of performing web searches and providing answers.
Step10: Generating the Assistant’s Response
with st.chat_message("assistant"):
st_cb = StreamlitCallbackHandler(st.container(), expand_new_thoughts=False)
try:
response = search_agent.run([{"role": "user", "content": prompt}], callbacks=[st_cb])
st.session_state.messages.append({'role': 'assistant', "content": response})
st.write(response)
except ValueError as e:
st.error(f"An error occurred: {e}")- st.chat_message(“assistant”): Displays the assistant’s response in the chat interface.
- StreamlitCallbackHandler: Manages how intermediate steps or thoughts are displayed in Streamlit.
- search_agent.run(): Executes the agent’s reasoning and tools to generate a response.
- Input: A formatted list containing the user’s prompt.
Ensures the app handles issues (e.g., invalid responses) gracefully, displaying an error message whennecessary.
Output
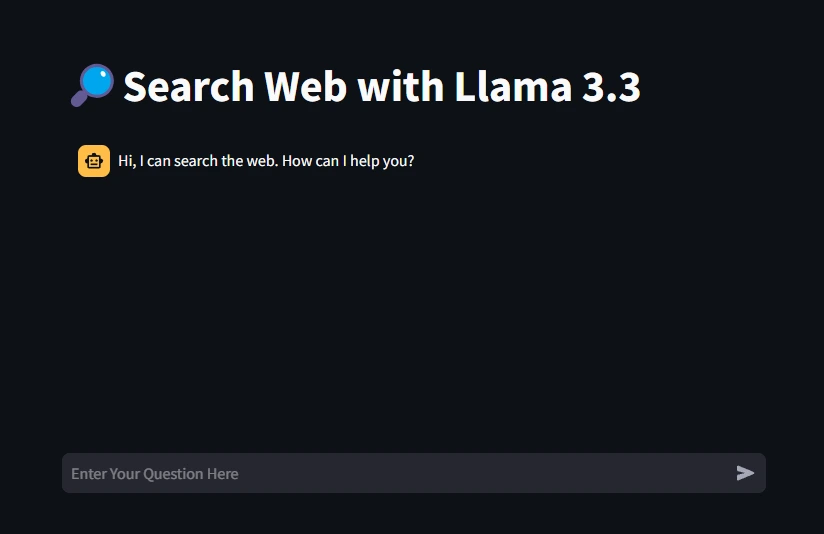
Testing the Webapp
- Input: What is Gradient Descent Algorithm
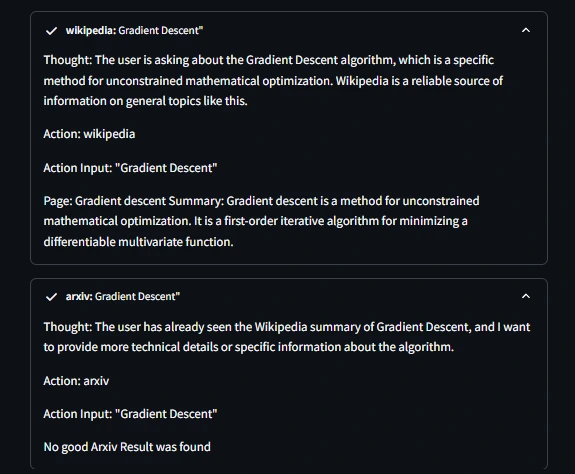

The Agent is providing thought output between both the tools
Get the Full Code in GitHub Repo Here
Conclusion
Building a web-searching agent with LangChain and Llama 3.3 demonstrates how the combination of cutting-edge AI with external knowledge sources such as ArXiv and Wikipedia can power real-world applications that bridge the gap between conversational AI and real-world applications. Users can effortlessly retrieve accurate, context-aware information with this approach. The project uses tools like Streamlit for user interaction and environment variables for security to provide a seamless and secure experience for users.
The modular design allows easy scoping, adapting the entire system to domains and even use cases. This modularity, especially in our AI-driven agents like this example, is how we create tremendous steps toward more intelligent systems that augment human capacities for capabilities in research and education; in fact, way further than that. This research serves as the base platform for building even smarter interactive tools that seize the high potential of AI in seeking knowledge.
Key Takeaways
- This project demonstrates how to combine a language model like Llama 3.3 with tools like ArXiv and Wikipedia to create a robust web-searching agent.
- Streamlit provides a simple way to build and deploy interactive web apps, making it ideal for chat-based tools.
- Environment variables keep sensitive credentials, like API keys, secure by preventing exposure in the codebase.
- It will handle parsing errors in the AI agents, ensuring a better reliability and user experience in the application.
- This approach ensures modularity through wrappers, query tools, and LangChain agents, allowing easy extension with additional tools or APIs.
Frequently Asked Questions
A. Llama 3.3 is a versatile language model capable of processing and understanding complex queries. It is used for its advanced reasoning abilities and natural language generation.
A. These platforms provide access to research papers and Data, making them ideal for a knowledge-enhanced web-searching agent.
A. Streamlit offers an intuitive framework to create a chat interface, enabling seamless interaction between the user and the AI agent.
A. Thanks to the modular nature of LangChain, we can integrate other tools to expand the agent’s capabilities.
A. We manage errors using a try-except block, ensuring the app provides meaningful feedback instead of crashing.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hi I’m Gourav, a Data Science Enthusiast with a medium foundation in statistical analysis, machine learning, and data visualization. My journey into the world of data began with a curiosity to unravel insights from datasets.