

Introduction
In an era where information is at our fingertips, the ability to ask a question and receive a precise answer has become crucial. Imagine having a system that understands the intricacies of language and delivers accurate responses to your queries in an instant. This article explores how to build such a powerful question-answer model using the Universal Sentence Encoder and the WikiQA dataset. By leveraging advanced embedding models, we aim to bridge the gap between human curiosity and machine intelligence, creating a seamless interaction that can revolutionize how we seek and obtain information.
Learning Objectives
- Gain proficiency in using embedding models like the Universal Sentence Encoder to transform textual data into high-dimensional vector representations.
- Understand the challenges and strategies involved in selecting and fine-tuning pre-trained models.
- Through hands-on experience, learners will implement a question-answering system that makes use of embedding models and cosine similarity.
- Understand the principles behind cosine similarity and its application in measuring the similarity between vectorized text representations.
This article was published as a part of the Data Science Blogathon.
Leveraging Embedding Models in NLP
We shall use embedded models which are one type of machine learning model widely used in natural language processing (NLP). This approach transforms texts into numerical formats that capture their meanings. Words, phrases or sentences are converted into numerical vectors termed as embeddings. Algorithms make use of these embeddings to understand and manipulate the text in many ways.
Understanding Embedding Models
Word embeddings represent words efficiently in a dense numerical format, where similar words receive similar encodings. Unlike manually setting these encodings, the model learns embeddings as trainable parameters—floating point values that it adjusts during training, similar to how it learns weights in a dense layer. Embeddings range from 300 for smaller models and datasets to larger dimensions like 1024 for larger models and datasets, allowing them to capture relationships between words. This higher dimensionality enables embeddings to encode detailed semantic relationships.
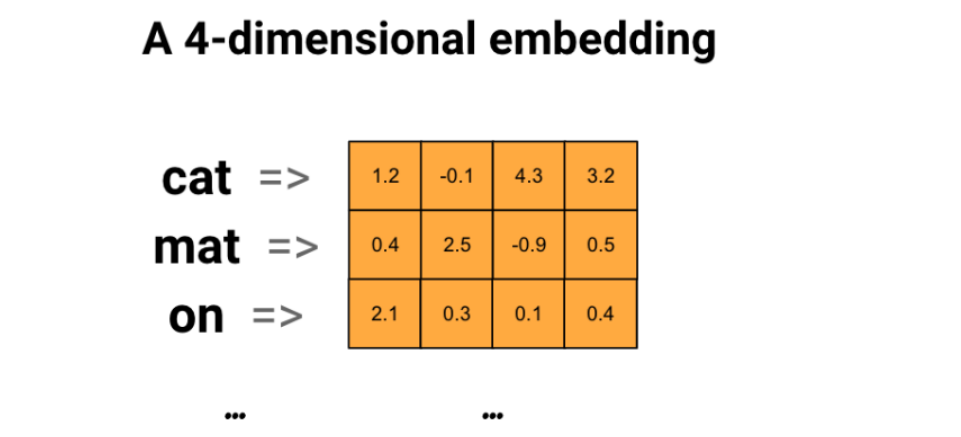
In a word embedding diagram, we portray each word as a 4-dimensional vector of floating point values. We can think of embeddings as a “lookup table,” where we store each word’s dense vector after training, allowing quick encoding and retrieval based on its corresponding vector representation.
Semantic Similarity: Measuring Meaning in Text
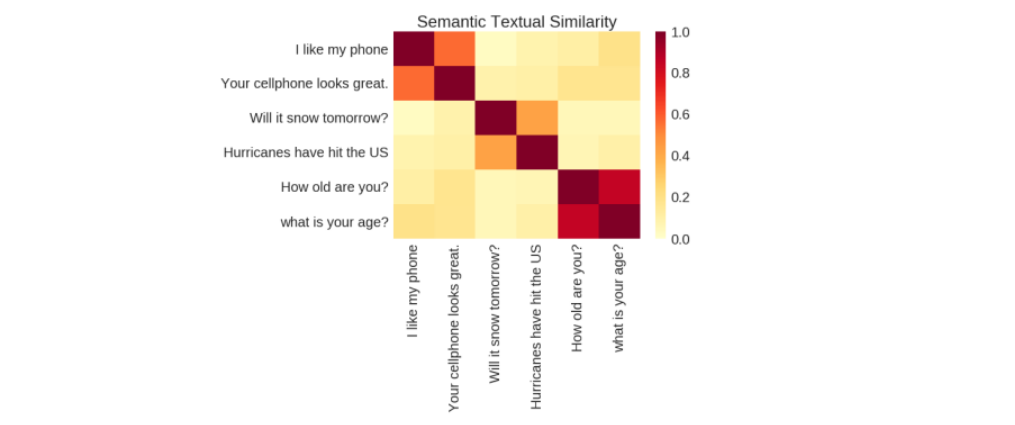
Semantic similarity is the measure of how closely two pieces of text convey the same meaning. It’s valuable because it helps systems understand the various ways people articulate ideas in language without requiring explicit definitions for each variation.
Universal Sentence Encoder for Enhanced Text Processing
In this project we will be making use of the Universal Sentence Encoder which transforms text into high-dimensional vectors useful for tasks like text classification, semantic similarity, and clustering among others. It’s optimized for processing text longer than single words . It is trained on diverse datasets and adapts to various natural language tasks. Inputting variable-length English text yields a 512-dimensional vector as output.
The following are example embedding output of 512 dimensions per sentence:
!pip install tensorflow tensorflow-hub
import tensorflow as tf
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
sentences = [
"The quick brown fox jumps over the lazy dog.",
"I am a sentence for which I would like to get its embedding"
]
embeddings = embed(sentences)
print(embeddings)
print(embeddings.numpy())Output:

This encoder employs a deep averaging network (DAN) for training, distinguishing itself from word-level embedding models by focusing on understanding the meaning of sequences of words, not just individual words. For more on text embeddings, consult TensorFlow’s Embeddings documentation. Further technical details can be found in the paper “Universal Sentence Encoder” here.
The module preprocesses text input as best as it can, so you don’t need to preprocess the data before applying it.

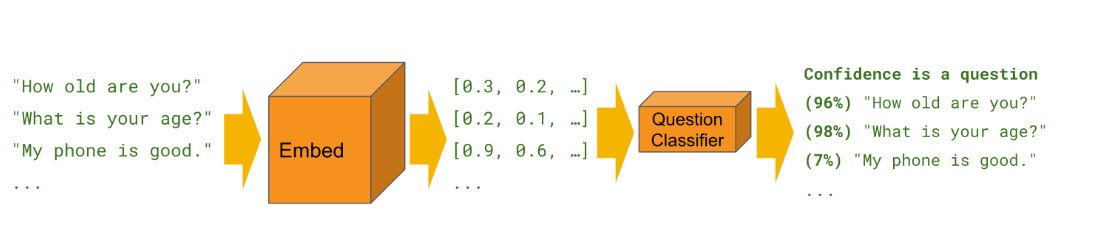
Developers partially trained the Universal Sentence Encoder with custom text classification tasks in mind. We can train these classifiers to perform a wide variety of classification tasks, often with a very small amount of labeled examples.
Code Implementation for a Question-Answer Generator
The dataset used for this code is from the WikiQA Dataset .
import pandas as pd
import tensorflow_hub as hub #provides pre-trained models and modules like the USE.
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# Load dataset (adjust the path accordingly)
df = pd.read_csv('/content/train.csv')
questions = df['question'].tolist()
answers = df['answer'].tolist()
# Load Universal Sentence Encoder
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
# Compute embeddings
question_embeddings = embed(questions)
answer_embeddings = embed(answers)
# Calculate similarity scores
similarity_scores = cosine_similarity(question_embeddings, answer_embeddings)
# Predict answers
predicted_indices = np.argmax(similarity_scores, axis=1) # finds the index of the answer with the highest similarity score.
predictions = [answers[idx] for idx in predicted_indices]
# Print questions and predicted answers
for i, question in enumerate(questions):
print(f"Question: {question}")
print(f"Predicted Answer: {predictions[i]}\n")

Let’s modify the code to ask custom questions print the most similar question and the predicted answer:
def ask_question(new_question):
new_question_embedding = embed([new_question])
similarity_scores = cosine_similarity(new_question_embedding, question_embeddings)
most_similar_question_idx = np.argmax(similarity_scores)
most_similar_question = questions[most_similar_question_idx]
predicted_answer = answers[most_similar_question_idx]
return most_similar_question, predicted_answer
# Example usage
new_question = "When was Apple Computer founded?"
most_similar_question, predicted_answer = ask_question(new_question)
print(f"New Question: {new_question}")
print(f"Most Similar Question: {most_similar_question}")
print(f"Predicted Answer: {predicted_answer}")Output:

New Question: When was Apple Computer founded?
Most Similar Question: When was Apple Computer founded.
Predicted Answer: Apple Inc., formerly Apple Computer, Inc., designs, develops, and sells consumer electronics, computer software, and personal computers. This American multinational corporation is headquartered in Cupertino, California.
Advantages of Using Embedding Models in NLP Tasks
- Many embedding models, like the Universal Sentence Encoder come pre-trained on vast amounts of data this reduces the need for extensive training on specific datasets and allowing quicker deployment thus saving computational resources.
- By representing text in a high-dimensional space embedding systems can recognize and match semantically similar phrases, even if they use different words such as synonyms and paraphrased questions.
- We can train many embedding models to work with multiple languages, making it easier to develop multilingual question-answering systems.
- Embedding systems simplify the process of feature engineering needed for machine learning models process by automatically learning the features from the data.
Challenges in Question-Answer Generator
- Choosing the right pre-trained model and fine-tuning parameters for specific use cases can be challenging.
- Handling large volumes of data efficiently in real-time applications requires careful optimization and can be challenging.
- Nuances, intricate detail and context misinterpretation in language that may lead to wrongly generated results.
Conclusion
Embedding models can thus improve question-answering systems. Converting the text into embeddings and calculating similarity scores helps the system accurately identify and predict relevant answers to user questions. This approach enhances the use cases of embedded models in NLP related tasks which involve human interaction.
Key Learnings
- Embedding models like the Universal Sentence Encoder offers tools for converting text into numerical representations.
- Using embedding based question answering system improves user interaction by delivering accurate and relevant responses.
- We face challenges like semantic ambiguity, diverse queries, and maintaining computational efficiency.
Frequently Asked Questions
A. Embedding models, like the Universal Sentence Encoder, turn text into detailed numerical forms called embeddings. These help systems understand and give accurate answers to user questions.
A. Many embedding models can work with multiple languages. We can use them in systems that answer questions in different languages, making these systems very flexible.
A. Embedding systems are good at recognizing and matching phrases such as synonyms and understanding different types of language tasks.
A. Choosing the right model and setting it up for specific tasks can be tricky. Also, managing large amounts of data quickly, especially in real-time situations, needs careful planning.
A. By turning text into embeddings and checking how similar they are, embedding models can give very accurate answers to user questions. This makes users happier because they get answers that fit exactly what they asked.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.