

Introduction
Function calling in large language models (LLMs) has transformed how AI agents interact with external systems, APIs, or tools, enabling structured decision-making based on natural language prompts. By using JSON schema-defined functions, these models can autonomously select and execute external operations, offering new levels of automation. This article will demonstrate how function calling can be implemented using Mistral 7B, a state-of-the-art model designed for instruction-following tasks.
Learning Outcomes
- Understand the role and types of AI agents in generative AI.
- Learn how function calling enhances LLM capabilities using JSON schemas.
- Set up and load Mistral 7B model for text generation.
- Implement function calling in LLMs to execute external operations.
- Extract function arguments and generate responses using Mistral 7B.
- Execute real-time functions like weather queries with structured output.
- Expand AI agent functionality across various domains using multiple tools.
This article was published as a part of the Data Science Blogathon.
What are AI Agents?
In the scope of Generative AI (GenAI), AI agents represent a significant evolution in artificial intelligence capabilities. These agents use models, such as large language models (LLMs), to create content, simulate interactions, and perform complex tasks autonomously. The AI agents enhance their functionality and applicability across various domains, including customer support, education, and medical domain.
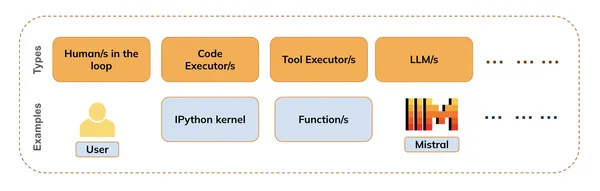
They can be of several types (as shown in the figure below) including :
- Humans in the loop (e.g. for providing feedback)
- Code executors (e.g. IPython kernel)
- Tool Executors (e.g. Function or API executions )
- Models (LLMs, VLMs, etc)
Function Calling is the combination of Code execution, Tool execution, and Model Inference i.e. while the LLMs handle natural language understanding and generation, the Code Executor can execute any code snippets needed to fulfill user requests.
We can also use the Humans in the loop, to get feedback during the process, or when to terminate the process.
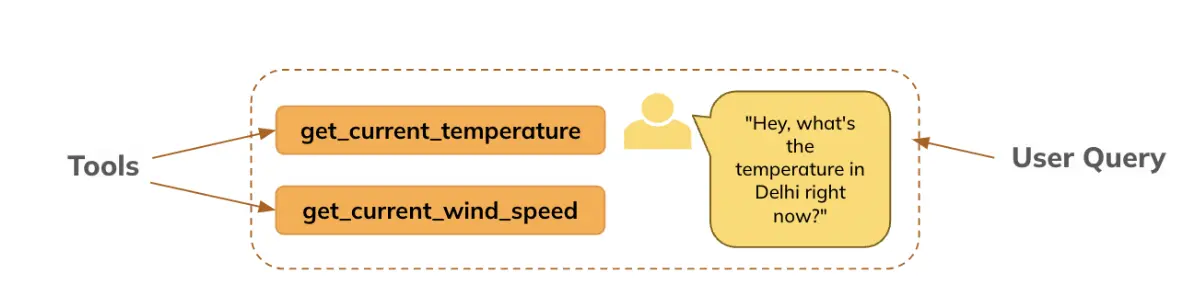
What is Function Calling in Large Language Models?
Developers define functions using JSON schemas (which are passed to the model), and the model generates the necessary arguments for these functions based on user prompts. For example: It can call weather APIs to provide real-time weather updates based on user queries (We’ll see a similar example in this notebook). With function calling, LLMs can intelligently select which functions or tools to use in response to a user’s request. This capability allows agents to make autonomous decisions about how to best fulfill a task, enhancing their efficiency and responsiveness.
This article will demonstrate how we used the LLM (here, Mistral) to generate arguments for the defined function, based on the question asked by the user, specifically: The user asks about the temperature in Delhi, the model extracts the arguments, which the function uses to get the real-time information (here, we’ve set to return a default value for demonstration purposes), and then the LLM generates the answer in simple language for the user.
Building a Pipeline for Mistral 7B: Model and Text Generation
Let’s import the necessary libraries and import the model and tokenizer from huggingface for inference setup. The Model is available here.
Importing Necessary Libraries
from transformers import pipeline ## For sequential text generation
from transformers import AutoModelForCausalLM, AutoTokenizer # For leading the model and tokenizer from huggingface repository
import warnings
warnings.filterwarnings("ignore") ## To remove warning messages from outputProviding the huggingface model repository name for mistral 7B
model_name = "mistralai/Mistral-7B-Instruct-v0.3"Downloading the Model and Tokenizer
- Since this LLM is a gated model, it’ll require you to sign up on huggingface and accept their terms and conditions first. After signing up, you can follow the instructions on this page to generate your user access token to download this model on your machine.
- After generating the token by following the above-mentioned steps, pass the huggingface token (in hf_token) for loading the model.
model = AutoModelForCausalLM.from_pretrained(model_name, token = hf_token, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained(model_name, token = hf_token)Implementing Function Calling with Mistral 7B
In the rapidly evolving world of AI, implementing function calling with Mistral 7B empowers developers to create sophisticated agents capable of seamlessly interacting with external systems and delivering precise, context-aware responses.
Step 1 : Specifying tools (function) and query (initial prompt)
Here, we’re defining the tools (function/s) whose information the model will have access to, for generating the function arguments based on the user query.
Tool is defined below:
def get_current_temperature(location: str, unit: str) -> float:
"""
Get the current temperature at a location.
Args:
location: The location to get the temperature for, in the format "City, Country".
unit: The unit to return the temperature in. (choices: ["celsius", "fahrenheit"])
Returns:
The current temperature at the specified location in the specified units, as a float.
"""
return 30.0 if unit == "celsius" else 86.0 ## We're setting a default output just for demonstration purpose. In real life it would be a working functionThe prompt template for Mistral needs to be in the specific format below for Mistral.
Query (the prompt) to be passed to the model
messages = [
{"role": "system", "content": "You are a bot that responds to weather queries. You should reply with the unit used in the queried location."},
{"role": "user", "content": "Hey, what's the temperature in Delhi right now?"}
]Step 2: Model Generates Function Arguments if Applicable
Overall, the user’s query along with the information about the available functions is passed to the LLM, based on which the LLM extracts the arguments from the user’s query for the function to be executed.

- Applying the specific chat template for mistral function calling
- The model generates the response which contains which function and which arguments need to be specified.
- The LLM chooses which function to execute and extracts the arguments from the natural language provided by the user.
inputs = tokenizer.apply_chat_template(
messages, # Passing the initial prompt or conversation context as a list of messages.
tools=[get_current_temperature], # Specifying the tools (functions) available for use during the conversation. These could be APIs or helper functions for tasks like fetching temperature or wind speed.
add_generation_prompt=True, # Whether to add a system generation prompt to guide the model in generating appropriate responses based on the tools or input.
return_dict=True, # Return the results in dictionary format, which allows easier access to tokenized data, inputs, and other outputs.
return_tensors="pt" # Specifies that the output should be returned as PyTorch tensors. This is useful if you're working with models in a PyTorch-based environment.
)
inputs = {k: v.to(model.device) for k, v in inputs.items()} # Moves all the input tensors to the same device (CPU/GPU) as the model.
outputs = model.generate(**inputs, max_new_tokens=128)
response = tokenizer.decode(outputs[0][len(inputs["input_ids"][0]):], skip_special_tokens=True)# Decodes the model's output tokens back into human-readable text.
print(response)Output : [{“name”: “get_current_temperature”, “arguments”: {“location”: “Delhi, India”, “unit”: “celsius”}}]
Step 3:Generating a Unique Tool Call ID (Mistral-Specific)
It is used to uniquely identify and match tool calls with their corresponding responses, ensuring consistency and error handling in complex interactions with external tools
import json
import random
import string
import reGenerate a random tool_call_id
It is used to uniquely identify and match tool calls with their corresponding responses, ensuring consistency and error handling in complex interactions with external tools.
tool_call_id = ''.join(random.choices(string.ascii_letters + string.digits, k=9))Append the tool call to the conversation
messages.append({"role": "assistant", "tool_calls": [{"type": "function", "id": tool_call_id, "function": response}]})print(messages)Output :

Step 4: Parsing Response in JSON Format
try :
tool_call = json.loads(response)[0]
except :
# Step 1: Extract the JSON-like part using regex
json_part = re.search(r'\[.*\]', response, re.DOTALL).group(0)
# Step 2: Convert it to a list of dictionaries
tool_call = json.loads(json_part)[0]
tool_callOutput : {‘name’: ‘get_current_temperature’, ‘arguments’: {‘location’: ‘Delhi, India’, ‘unit’: ‘celsius’}}
[Note] : In some cases, the model may produce some texts as well alongwith the function information and arguments. The ‘except’ block takes care of extracting the exact syntax from the output
Step 5: Executing Functions and Obtaining Results
Based on the arguments generated by the model, you pass them to the respective function to execute and obtain the results.
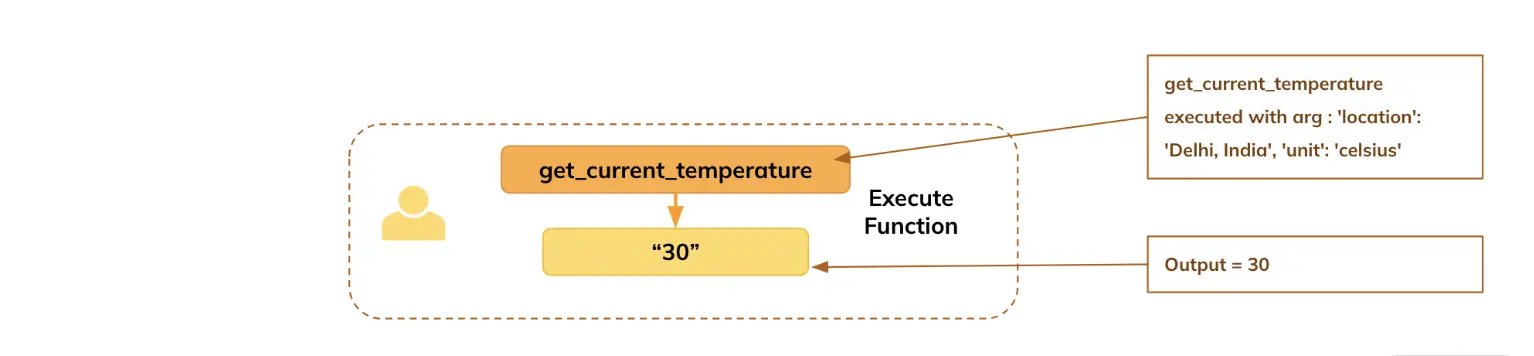
function_name = tool_call["name"] # Extracting the name of the tool (function) from the tool_call dictionary.
arguments = tool_call["arguments"] # Extracting the arguments for the function from the tool_call dictionary.
temperature = get_current_temperature(**arguments) # Calling the "get_current_temperature" function with the extracted arguments.
messages.append({"role": "tool", "tool_call_id": tool_call_id, "name": "get_current_temperature", "content": str(temperature)})Step 6: Generating the Final Answer Based on Function Output
## Now this list contains all the information : query and function details, function execution details and the output of the function
print(messages)Output

Preparing the prompt for passing whole information to the model
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = {k: v.to(model.device) for k, v in inputs.items()}Model Generates Final Answer
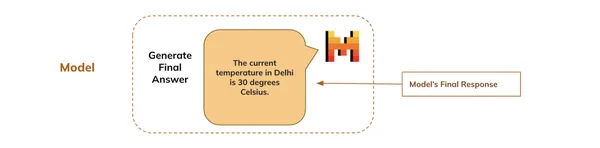
Finally, the model generates the final response based on the entire conversation that starts with the user’s query and shows it to the user.
- inputs : Unpacks the input dictionary, which contains tokenized data the model needs to generate text.
- max_new_tokens=128: Limits the generated response to a maximum of 128 new tokens, preventing the model from generating excessively long responses
outputs = model.generate(**inputs, max_new_tokens=128)
final_response = tokenizer.decode(outputs[0][len(inputs["input_ids"][0]):],skip_special_tokens=True)
## Final response
print(final_response)Output: The current temperature in Delhi is 30 degrees Celsius.
Conclusion
We built our first agent that can tell us real-time temperature statistics across the globe! Of course, we used a random temperature as a default value, but you can connect it to weather APIs that fetch real-time data.
Technically speaking, based on the natural language query by the user, we were able to get the required arguments from the LLM to execute the function, get the results out, and then generate a natural language response by the LLM.
What if we wanted to know the other factors like wind speed, humidity, and UV index? : We just need to define the functions for those factors and pass them in the tools argument of the chat template. This way, we can build a comprehensive Weather Agent that has access to real-time weather information.
Key Takeaways
- AI agents leverage LLMs to perform tasks autonomously across diverse fields.
- Integrating function calling with LLMs enables structured decision-making and automation.
- Mistral 7B is an effective model for implementing function calling in real-world applications.
- Developers can define functions using JSON schemas, allowing LLMs to generate necessary arguments efficiently.
- AI agents can fetch real-time information, such as weather updates, enhancing user interactions.
- You can easily add new functions to expand the capabilities of AI agents across various domains.
Frequently Asked Questions
A. Function calling in LLMs allows the model to execute predefined functions based on user prompts, enabling structured interactions with external systems or APIs.
A. Mistral 7B excels at instruction-following tasks and can autonomously generate function arguments, making it suitable for applications that require real-time data retrieval.
A. JSON schemas define the structure of functions used by LLMs, allowing the models to understand and generate necessary arguments for those functions based on user input.
A. You can design AI agents to handle various functionalities by defining multiple functions and integrating them into the agent’s toolset.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.