


Image by Author | DALLE-3
It has always been tedious to train Large Language Models. Even with extensive support from public platforms like HuggingFace, the process includes setting up different scripts for each pipeline stage. From setting up data for pretraining, fine-tuning, or RLHF to configuring the model from quantization and LORAs, training an LLM requires laborious manual efforts and tweaking.
The recent release of LLama-Factory in 2024 aims to solve the exact problem. The GitHub repository makes setting up model training for all stages in an LLM lifecycle extremely convenient. From pretraining to SFT and even RLHF, the repository provides built-in support for the setup and training of all the latest available LLMs.
Supported Models and Data Formats
The repository supports all the recent models including LLama, LLava, Mixtral Mixture-of-Experts, Qwen, Phi, and Gemma among others. The full list can be found here. It supports pretraining, SFT, and major RL techniques including DPO, PPO, and, ORPO allows all the latest methodologies from full-finetuning to freeze-tuning, LORAs, QLoras, and Agent Tuning.
Moreover, they also provide sample datasets for each training step. The sample datasets generally follow the alpaca template even though the sharegpt format is also supported. We highlight the Alpaca data formatting below for a better understanding of how to set up your proprietary data.
Note that when using your data, you must edit and add information about your data file in the dataset_info.json file in the Llama-Factory/data folder.
Pre-training Data
The data provided is kept in a JSON file and only the text column is used for training the LLM. The data needs to be in the format given below to set up pre-training.
[
{"text": "document"},
{"text": "document"}
]
Supervised Fine-Tuning Data
In SFT data, there are three required parameters; instruction, input, and output. However, system and history can be passed optionally and will be used to train the model accordingly if provided in the dataset.
The general alpaca format for SFT data is as given:
[
{
"instruction": "human instruction (required)",
"input": "human input (optional)",
"output": "model response (required)",
"system": "system prompt (optional)",
"history": [
["human instruction in the first round (optional)", "model response in the first round (optional)"],
["human instruction in the second round (optional)", "model response in the second round (optional)"]
]
}
]
Reward Modeling Data
Llama-Factory provides support to train an LLM for preference alignment using RLHF. The data format must provide two different responses for the same instruction, which must highlight the preference of the alignment.
The better aligned response is passed to the chosen key and the worse response is passed to the rejected parameter. The data format is as follows:
[
{
"instruction": "human instruction (required)",
"input": "human input (optional)",
"chosen": "chosen answer (required)",
"rejected": "rejected answer (required)"
}
]
Setup and Installation
The GitHub repository provides support for easy installation using a setup.py and requirements file. However, it is advised to use a clean Python environment when setting up the repository to avoid dependency and package clashes.
Even though Python 3.8 is a minimum requirement, it is recommended to install Python 3.11 or above. Clone the repository from GitHub using the command below:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
We can now create a fresh Python environment using the commands below:
python3.11 -m venv venv
source venv/bin/activate
Now, we need to install the required packages and dependencies using the setup.py file. We can install them using the command below:
pip install -e ".[torch,metrics]"
This will install all required dependencies including torch, trl, accelerate, and other packages. To ensure correct installation, we should now be able to use the command line interface for Llama-Factory. Running the command below should output the usage help information on the terminal as shown in the image.
This should be printed on the command line if the installation was successful.
Finetuning LLMs
We can now start training an LLM! This is as easy as writing a configuration file and invoking a bash command.
Note that a GPU is a must to train an LLM using Llama-factory.
We choose a smaller model to save on GPU memory and training resources. In this example, we will perform LORA-based SFT for Phi3-mini-Instruct. We choose to create a yaml configuration file but you can use a JSON file as well.
Create a new config.yaml file as follows. This configuration file is for SFT training, and you can find more examples of various methods in the examples directory.
### model
model_name_or_path: microsoft/Phi-3.5-mini-instruct
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: alpaca_en_demo
template: llama3
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/phi-3/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
Although it is self-explanatory, we need to focus on two important parts of the configuration file.
Configuring Dataset for Training
The given name of the dataset is a key parameter. Further details for the dataset need to be added to the dataset_info.json file in the data directory before training. This information includes necessary information about the actual data file path, the data format followed, and the columns to be used from the data.
For this tutorial, we use the alpaca_demo dataset which contains questions and answers related to English. You can view the complete dataset here.
The data will then be automatically loaded from the provided information. Moreover, the dataset key accepts a list of comma-separated values. Given a list, all the datasets will be loaded and used to train the LLM.
Configuring Model Training
Changing the training type in Llama-Factory is as easy as changing a configuration parameter. As shown below, we only need the below parameters to set up LORA-based SFT for the LLM.
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
We can replace SFT with pre-training and reward modeling with exact configuration files available in the examples directory. You can easily change the SFT to reward modeling by changing the given parameters.
Start Training an LLM
Now, we have everything set up. All that is left is invoking a bash command passing the configuration file as a command line input.
Invoke the command below:
llamafactory-cli train config.yaml
The program will automatically set up all required datasets, models, and pipelines for the training. It took me 10 minutes to train one epoch on a TESLA T4 GPU. The output model is saved in the output_dir provided in the config.yaml.
Inference
The inference is even simpler than training a model. We need a configuration file similar to training providing the base model and the path to the trained LORA adapter.
Create a new infer_config.yaml file and provide values for the given keys:
model_name_or_path: microsoft/Phi-3.5-mini-instruct
adapter_name_or_path: saves/phi3-8b/lora/sft/ # Path to trained model
template: llama3
finetuning_type: lora
We can chat with the trained model directly on the command line with this command:
llamafactory-cli chat infer_config.yaml
This will load the model with the trained adaptor and you can easily chat using the command line, similar to other packages like Ollama.
A sample response on the terminal is shown in the image below:
Result of Inference
WebUI
If that was not simple enough, Llama-factory provides a no-code training and inference option with the LlamaBoard.
You can start the GUI using the bash command:
This starts a web-based GUI on localhost as shown in the image. We can choose the model, and training parameters, load and preview the dataset, set hyperparameters, train and infer all on the GUI.
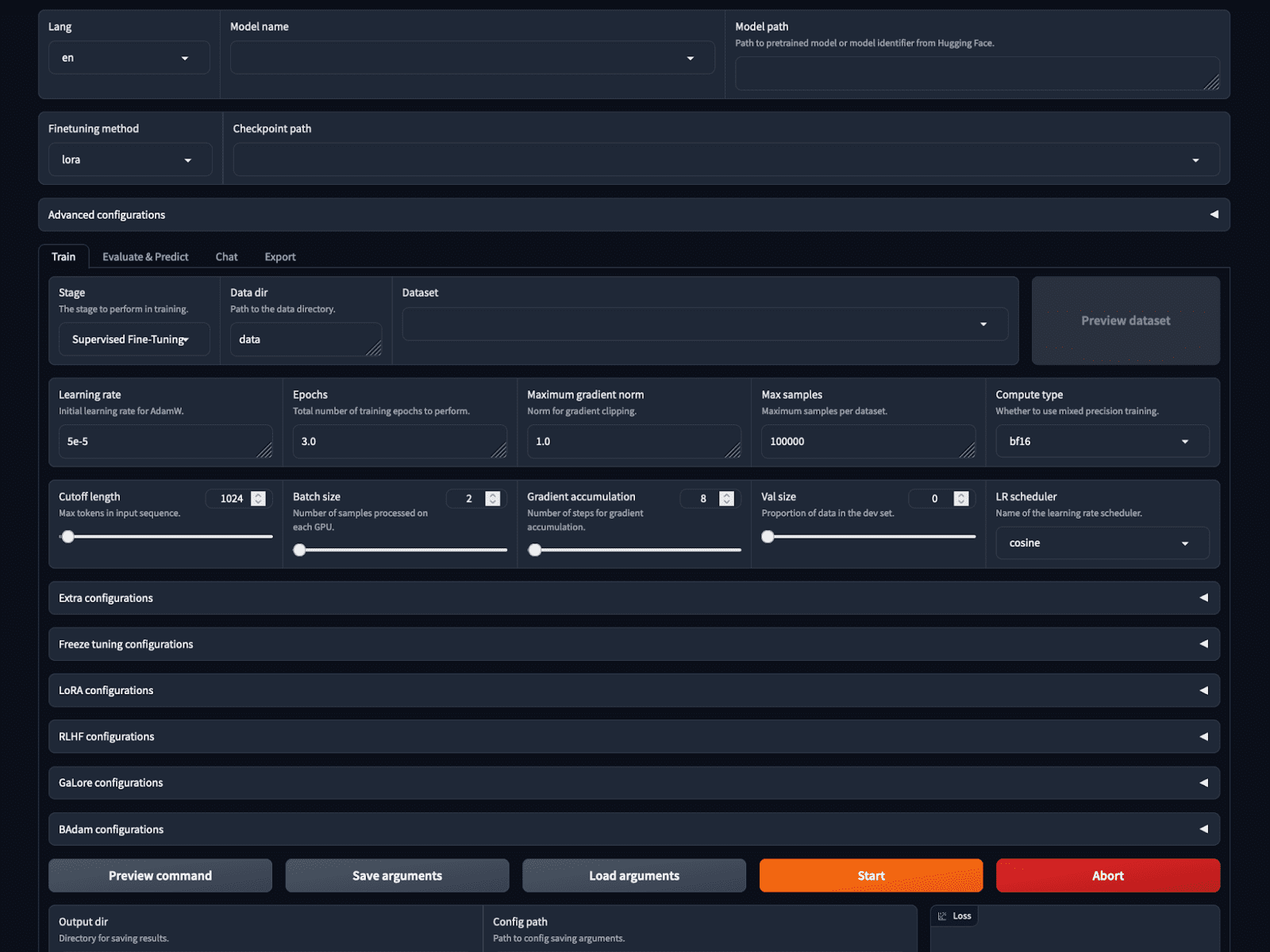
Screenshot of the LlamaBoard WebUI
Conclusion
Llama-factory is rapidly becoming popular with over 30 thousand stars on GitHub now. It makes it considerably simpler to configure and train an LLM from scratch removing the need for manually setting up the training pipeline for various methods.
It supports all the latest methods and models and still claims to be 3.7 times faster than ChatGLM’s P-Tuning while utilizing less GPU memory. This makes it easier for normal users and enthusiasts to train their LLMs using minimal code.
Kanwal Mehreen Kanwal is a machine learning engineer and a technical writer with a profound passion for data science and the intersection of AI with medicine. She co-authored the ebook “Maximizing Productivity with ChatGPT”. As a Google Generation Scholar 2022 for APAC, she champions diversity and academic excellence. She’s also recognized as a Teradata Diversity in Tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having founded FEMCodes to empower women in STEM fields.
Our Top 3 Partner Recommendations
![]()
![]() 1. Best VPN for Engineers – Stay secure & private online with a free trial
1. Best VPN for Engineers – Stay secure & private online with a free trial
![]()
![]() 2. Best Project Management Tool for Tech Teams – Boost team efficiency today
2. Best Project Management Tool for Tech Teams – Boost team efficiency today
![]()
![]() 4. Best Network Management Tool – Best for Medium to Large Companies
4. Best Network Management Tool – Best for Medium to Large Companies