

Introduction
If you’ve worked with Large Language Models (LLMs), you’re likely familiar with the challenges of tuning them to respond precisely as desired. This struggle often stems from the models’ limited reasoning capabilities or difficulty in processing complex prompts. Despite being trained on vast datasets, LLMs can falter with nuanced or context-heavy queries, leading to frustration among developers. The core challenge is to balance the model’s generalization with the need for specific, accurate responses.
LLMs have indeed made remarkable advances in natural language processing, enabling them to generate human-like text, engage in conversations, and even assist with decision-making. Nevertheless, their logical reasoning abilities—such as problem decomposition, cause-and-effect understanding, and maintaining consistency—still have room for growth. Improved reasoning is vital for tasks like scientific research and strategic planning, where output precision and coherence are crucial. It is evident how important it is to enhance reasoning in LLMs, noting that it’s crucial for applications requiring complex problem-solving, decision-making, and understanding of cause-and-effect relationships. This article talks all about how we can improve the reasoning capabilities of LLMs through Prompt Engineering, and it is based on the recent talks by Anant Agarwal at the Data Hack Summit 2024, which focused on Enhancing Logical Reasoning in LLMs Through Prompt Engineering.

Overview
- Prompt engineering is a powerful tool for enhancing LLM reasoning without extensive retraining.
- Chain of Thought (CoT) prompting is a key technique for guiding LLMs through step-by-step reasoning.
- Least to Most Successive Prompting effectively breaks down complex problems for LLMs to solve sequentially.
- Step-back Prompting encourages LLMs to consider high-level concepts before diving into specific problems.
- Interleaved Retrieval with CoT Prompting combines information retrieval with reasoning for more comprehensive responses.
Why Reasoning is Important for LLMs?
Reasoning is considered a cornerstone of intelligence. While LLMs excel at many tasks, their reasoning ability is crucial for applications requiring complex problem-solving, decision-making, and understanding of cause-and-effect relationships. Improved reasoning capabilities can lead to more reliable and trustworthy AI systems across various domains. Here’s why reasoning capabilities are vital for LLMs:
- Complex Problem Solving: Reasoning enables LLMs to break down and solve complex, multi-step problems more effectively.
- Decision Making: Logical reasoning is essential for making informed decisions, particularly in fields like strategic planning and medical diagnosis.
- Understanding Causality: It helps LLMs grasp cause-and-effect relationships, which is important for predicting outcomes and analyzing events.
- Improved Explanations: Reasoning allows LLMs to provide clear, logical explanations, enhancing transparency and user trust.
- Handling Ambiguity: LLMs with strong reasoning can navigate ambiguous data and queries, offering more reliable responses.
- Generalization: Reasoning aids in applying learned knowledge to new situations, improving the versatility of LLMs.
- Fact-Checking and Consistency: It helps maintain internal consistency and accuracy, reducing contradictions or misinformation.
- Ethical Considerations: Strong reasoning enables LLMs to navigate ethical dilemmas, crucial as AI integrates more into decision-making.
- Scientific and Mathematical Applications: It is crucial for solving logical proofs and equations in fields like math and science.
- Creative Problem Solving: Reasoning fosters creativity by enabling LLMs to combine ideas logically in novel ways.
- Improved Human-AI Interaction: LLMs with good reasoning skills can engage in more meaningful, context-aware dialogues with humans.
- Robustness Against Adversarial Inputs: Better reasoning makes LLMs more resilient against misleading or adversarial inputs.
Enhancing reasoning in LLMs leads to more powerful, versatile, and trustworthy AI systems that better understand and interact with the world, closely resembling human cognition.
Also read: What are Large Language Models(LLMs)?
Limitations of LLMs in Reasoning
LLMs are trained as next-token prediction models, not as dedicated reasoning engines. This fundamental architecture can limit their ability to perform complex logical operations, especially when faced with multi-step problems or tasks requiring the integration of multiple pieces of information. Understanding these limitations is crucial for developing effective strategies to enhance their reasoning capabilities. Here’s an in-depth look at the key limitations:
Next-Token Prediction Architecture
- LLMs are fundamentally designed as next-token prediction models, not as dedicated reasoning engines.
- This architecture can lead to difficulties in maintaining long-term coherence and logical consistency across extended reasoning chains.
- The models may struggle to backtrack or revise earlier steps in a reasoning process, primarily focusing on generating the next most probable token.
Lack of Causal Understanding
- LLMs often struggle to distinguish correlation from causation.
- They may generate plausible-sounding but logically flawed explanations for phenomena, as they don’t understand cause-and-effect relationships.
Difficulty with Abstract Reasoning
- While LLMs excel at pattern recognition within their training data, they often struggle with abstract reasoning tasks that require generalization beyond their training examples.
- This can lead to difficulties in solving novel problems or applying learned concepts to unfamiliar contexts.
Inconsistency in Multi-Step Reasoning
- LLMs may perform well in the initial steps of a reasoning process but lose coherence or introduce contradictions in later steps.
- They often lack a global “understanding” of the entire reasoning chain, leading to locally plausible but globally inconsistent conclusions.
Vulnerability to Biases and Spurious Correlations
- LLMs can pick up and amplify biases present in their training data.
- They may rely on superficial patterns or spurious correlations rather than deep, logical reasoning.
Difficulty with Quantitative Reasoning
- Many LLMs struggle with precise numerical calculations or mathematical proofs.
- They may provide approximations or qualitative answers where exact quantitative reasoning is required.
Despite their vast knowledge, they often struggle with commonsense reasoning, missing simple logical implications due to a lack of real-world grounding. LLMs can also generate inaccurate information with high confidence, a phenomenon known as hallucination, leading to false logical conclusions. Context length limitations further hinder their reasoning capabilities, restricting their ability to maintain consistency over long passages or complex problems. Additionally, LLMs typically struggle with tasks requiring formal symbolic manipulation, such as advanced mathematics or logic, and often fail when reasoning about negations or hypothetical scenarios.
Unlike human reasoners, they cannot independently seek out additional information and are limited to the knowledge in their training data and provided prompts. Furthermore, LLMs lack meta-cognitive abilities, meaning they cannot assess their own reasoning processes or recognize logical errors. These limitations highlight the importance of ongoing research and development to enhance the reasoning capabilities of LLMs, including improvements in prompt engineering, model architecture, and the integration of hybrid systems.
Also Read: Beginner’s Guide to Build Large Language Models from Scratch
Existing benchmarks to measure LLM reasoning capabilities

Large language models (LLMs) often seem to store intelligence, but they struggle to reason out simple things like humans do. Unlike humans, LLMs only reason effectively when provided with the right context. This limitation arises from their design: they primarily serve as next-token prediction models rather than reasoning engines. Despite this, LLMs perform almost magical tasks, demonstrating abilities beyond their intended design. As model size increases, reasoning in LLMs becomes more evident, emerging as a capability. Smaller models struggle with reasoning tasks, so fine-tuning larger models is more effective than smaller ones using techniques like LoRA (Low-Rank Adaptation) or FLORA (Fine-tuning LLMs with LoRA). (Wei et al., 2022). Leveraging larger models is generally recommended for tasks that demand advanced reasoning. Researchers assess LLMs’ reasoning abilities through several established benchmarks.
Several benchmarks have been developed to assess the reasoning capabilities of LLMs:
- ARC Challenge: A multi-part Science question task with varying difficulty levels (easy and advanced questions). Here, LLMs are observed responding to these challenges without providing any examples.
- HellaSwag: It tests common-sense reasoning abilities. Here, LLMs are given simple tasks that humans inherently can answer, but we check their capabilities to understand the context.
- Grade School Math Problems (GSM8K): An 8,000-question benchmark for grade school math problems.
- Discrete Reasoning over Paragraphs (DROP): A reading comprehension dataset with 96,000 questions requiring multi-step reasoning.
Note: All the methods we explain will be implemented using the annotated DROP dataset in LangChain provided by Dua et al. To run the code, you only need the HuggingFace API Token.
Prompt Engineering for Improved Reasoning
Prompt engineering has emerged as a powerful technique to enhance the reasoning capabilities of LLMs without the need for fine-tuning or retraining.
Here’s a comparison between Standard Prompting and Chain of Thought (CoT) Prompting based on the transcript provided:
Standard Prompting
- Approach: In standard prompting, the model is given a single example or instruction, expecting it to provide the correct answer directly.
- Example Provided: The transcript mentions a simple problem where “Roger has five tennis balls and buys two more cans of tennis balls, each can containing three balls.” The standard prompt asks, “How many tennis balls does Roger have?” The expected answer is 11.
- Issue: The model (GPT-3.5 in this case) struggles to answer a subsequent, similarly structured question correctly. This highlights a limitation in reasoning or understanding the problem without further guidance.
- Result: Standard prompting often fails in more complex reasoning tasks because it does not guide the model through the reasoning process.
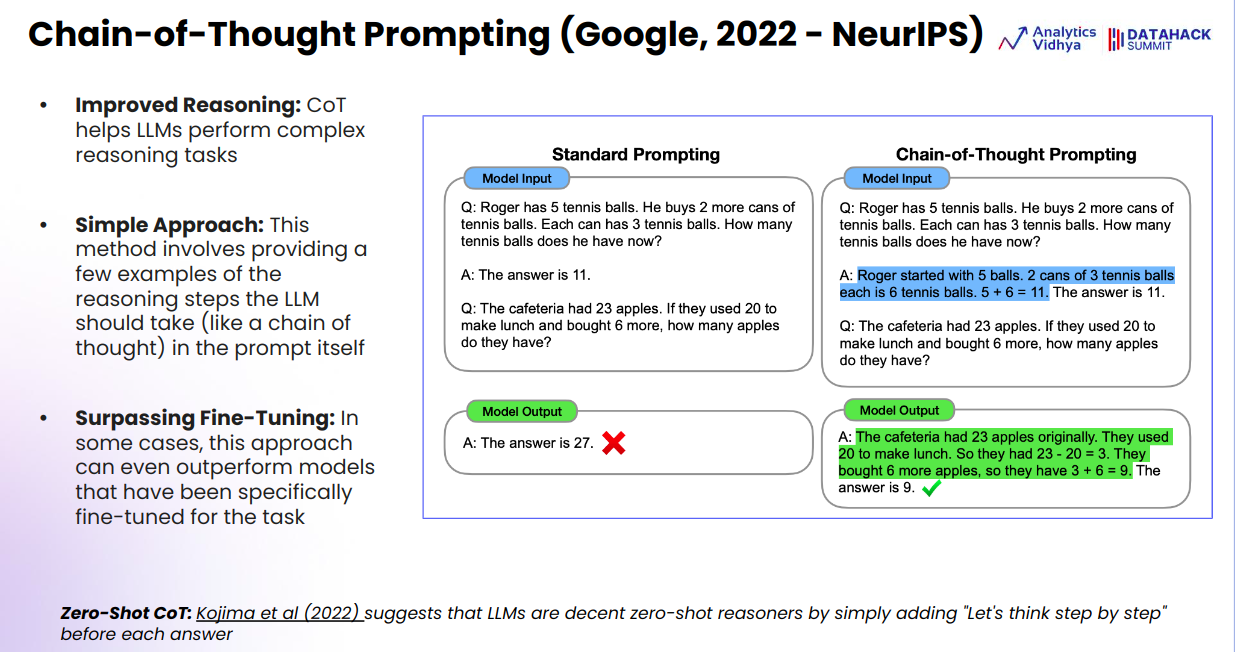
Chain of Thought (CoT) Prompting
- Approach: CoT prompting involves breaking down the problem-solving process into smaller, logical steps, guiding the model to think through the problem step by step.
- Implementation: In the CoT method, the model is prompted with a thought process instead of just asking for the final answer. For example, it might break down the tennis ball problem by first calculating the total number of balls Roger buys and then adding that to the existing number.
- Benefits:
- Guidance: By explicitly instructing the model to think step by step, it follows a logical sequence that leads to the correct answer.
- Effectiveness: CoT prompting can sometimes outperform even fine-tuned models, as it leverages the model’s inherent reasoning capabilities without requiring additional training.
- Zero-Shot Reasoning: Research mentioned in the transcript (by a Japanese scientist Kojima) suggests that LLMs are capable of decent zero-shot reasoning when guided through a step-by-step process. This means they can solve new problems they haven’t been explicitly trained on if given the right prompts.
Comparison Summary
- Standard Prompting is straightforward but often inadequate for complex reasoning tasks, as it lacks the necessary guidance for the model.
- CoT Prompting enhances the model’s reasoning ability by providing a structured approach to problem-solving, leading to better performance in tasks requiring logical reasoning.
How can LLMs Act as Optimizers?

In a 2024 paper released by Google, researchers evaluated various prompting techniques on the Great School Math data benchmark. The baseline method used was the “let’s think step-by-step” approach from Kojima et al. (2022), which achieved the highest accuracy without any examples (zero-shot). This method involves prompting the model to “take a deep breath and work on the problem step by step.”
Other techniques, such as “break this down” with PaLM 2L, yielded slightly lower results. The paper focuses on optimizing prompts to address reasoning questions effectively. Researchers explored iterative methods to determine the most effective prompt strings for answering questions, as understanding the model’s inner workings can be challenging.
Here’s the research paper:

Here’s the Link: Large Language Models as Optimizers
Other Prompt Engineering Techniques
Beyond Chain of Thought prompting, several other techniques have shown promise in enhancing LLM reasoning capabilities:
Least to Most Successive Prompting
This technique involves decomposing complex problems into sub-questions, solving them sequentially, and using the answers to build up to the final solution. It’s particularly useful for problems that are too complex for standard CoT prompting.
A technique introduced at ICLR addresses limitations in Chain of Thought (CoT) prompting for complex problems. This technique, called “Least to Most,” involves a two-step process for handling more intricate questions.
- Decomposition: In the first step, the large language model (LLM) breaks down the main question into smaller sub-questions. The LLM does not solve these questions at this stage but simply identifies and lists them.
- Sequential Solving: In the second step, the LLM solves these sub-questions one by one, using the answers from previous sub-questions to inform the next ones.

For instance, suppose the main question is about calculating the number of times Amy can slide down a slide within a given timeframe. In that case, the LLM first determines the time taken for each slide (sub-question) and then uses this information to solve the main problem.
The technique is noted for its simplicity and effectiveness, and while it is generally successful, there are instances where the LLM’s accuracy is not perfect. The process can be implemented by generating sub-questions, solving them iteratively, and using formats to guide the LLM through problem-solving.
Overall, the “Least to Most” technique improves problem-solving accuracy in complex scenarios, achieving an accuracy of 91.4% compared to 94% with Chain of Thought prompting.
To see how this actually works in practice, go through the given code – Least-to-Most Prompting
Successive Prompting

Here’s the Link: Successive Prompting for Decomposing Complex Questions
Here, we are discussing the technique called “successive prompting,” developed by a researcher – Dheera Dua, currently at Google DeepMind but originally conceived before their tenure at the company. This technique was presented at the EMNLP conference and contrasted with the “least to most” prompting method.
In “least to most” prompting, all sub-questions of a complex problem are identified and answered sequentially. In contrast, “successive prompting” decouples the question-answering process. Instead of identifying all sub-questions at once, it identifies and answers one sub-question at a time, iterating until the final answer is reached. This method is divided into two stages: question decomposition and question answering.
Decomposition Stage
In the question decomposition stage, the task is to identify the next sub-question. This step is not about finding the answer but determining which sub-question should be tackled next. Once identified, the question-answering stage involves solving that sub-question. This iterative process continues until all sub-questions are answered, leading to the final solution.
Also, the practical implementation challenge is that the length of prompts can make it difficult to maintain focus on the most important parts of the problem. The solution proposed involves a standardized format to help the model identify structure and relevance. However, this technique may face limitations in complex real-life applications, especially where hallucinations (incorrect or irrelevant outputs from the model) are a concern.
The technique was tested with a specific example, identifying sub-questions and attempting to answer them. While the method showed some potential, it only achieved 82% accuracy, suggesting that it may not always outperform simpler methods like “least to most.” The discussion also touches on potential improvements, such as incorporating retrieval-augmented generation (RAG) to enhance the relevance of the examples used in each iteration.
While successive prompting provides a flexible, iterative approach to problem-solving, its effectiveness varies with context and the problem’s nature.
Step-back Prompting
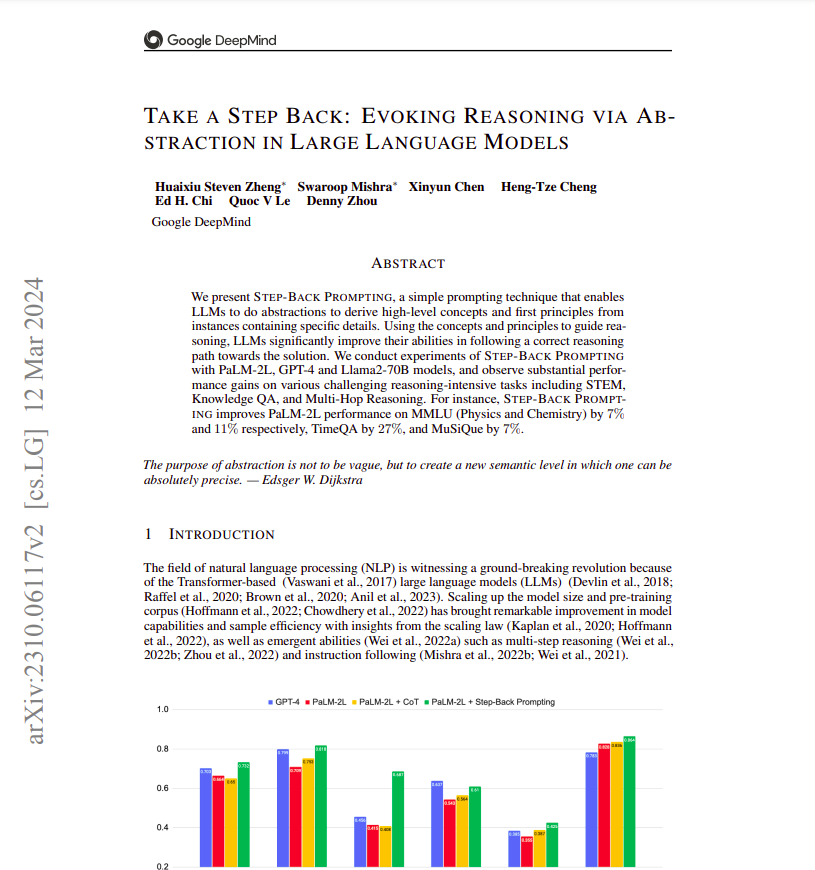
Here’s the link: Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
Step-back prompting encourages the LLM to consider high-level concepts or principles before attempting to solve the specific problem. This approach can be especially effective for domain-specific reasoning tasks. It is a method for improving the accuracy and effectiveness of large language models (LLMs). This approach contrasts with other methods like Chain of Thought (CoT) and prompt decomposition.
Step-back prompting first identifies key concepts or principles before solving the main question. For example, instead of directly answering a question about an ideal gas’s pressure, the LLM identifies relevant physics principles, then uses this understanding to address the main question.
Also, the step-back prompting is particularly useful in strategic analysis scenarios, such as developing a go-to-market (GTM) strategy. Instead of decomposing the problem into smaller parts, one should first determine a general strategic principle (the “step back question”) before answering the specific question.
Moreover, It emphasizes that combining step-back prompting with retrieval-augmented generation (RAG) often yields better results than fine-tuning models from scratch. They also outline a structured prompt with examples, a main question, and a step-back question to guide the LLM in generating accurate responses. Finally, a comparison of different prompting techniques shows that step-back prompting, while effective, performs slightly lower than the “least to most” method in terms of accuracy.
In a nutshell, when iterating over the step-back prompting technique, it achieves an accuracy of 81% on the specific dataset being used. In comparison, standard prompting yields an accuracy of 74%, while the Chain of Thought method reaches 90%. The “least to most” approach performs best, with slightly lower results for the successive prompting and step-back techniques.
Interleaved Retrieval with CoT Prompting
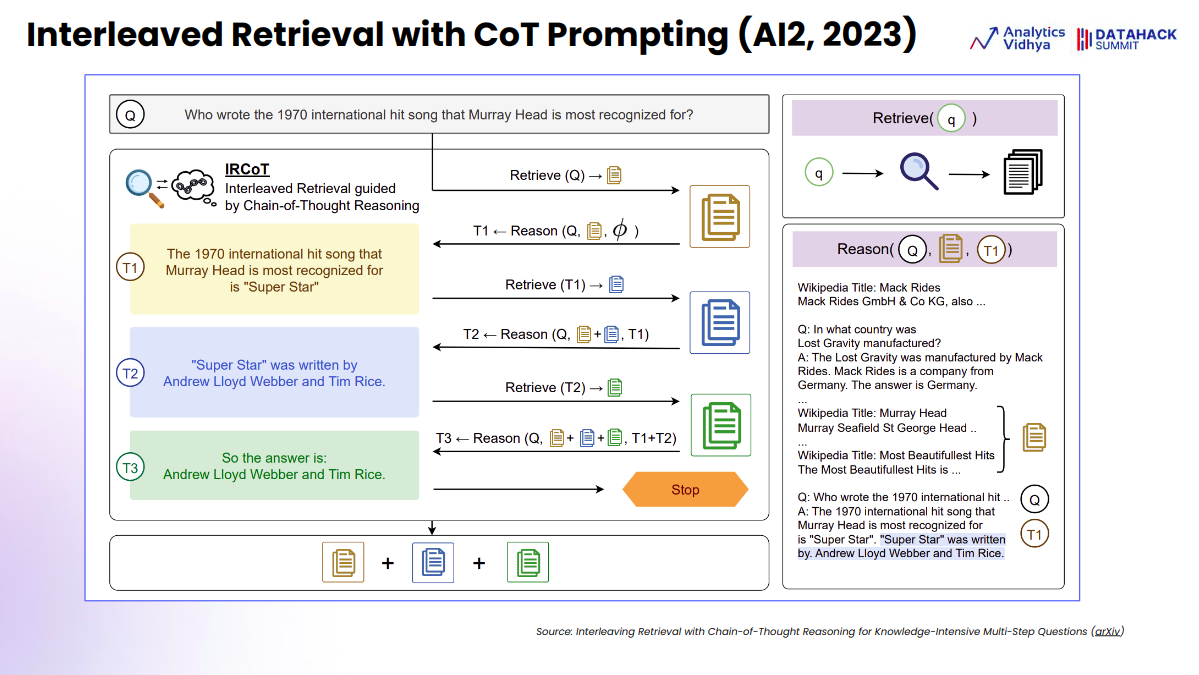
Here, we will discuss a process called “interleaved retrieval with Chain of Thought (CoT) prompting,” which combines information retrieval with reasoning to answer complex questions. This method operates as follows:
- Initial Query and Retrieval: A question is posed, and the first step involves retrieving a relevant document chunk to augment the prompt.
- Reasoning and Output Generation (T1): Based on the retrieved document and the question, the LLM (Large Language Model) generates an output (T1).
- Subsequent Retrieval and Reasoning: The LLM then automatically retrieves another document needed to answer the question, reasoning again with this new information and the previous output to generate the next response (T2).
- Further Iterations (T3): This process of retrieval and reasoning continues until enough relevant documents are gathered (T3) to answer the main question comprehensively.
- Final Response: The outputs from all steps (T1, T2, T3) are combined to form the final response.
The current implementation lacks steps such as determining the specific sub-questions and ensuring that the LLM’s responses fully answer the main question. These steps need to be refined further to improve the process.

Here’s the link: Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
Ensemble Techniques with Majority Voting
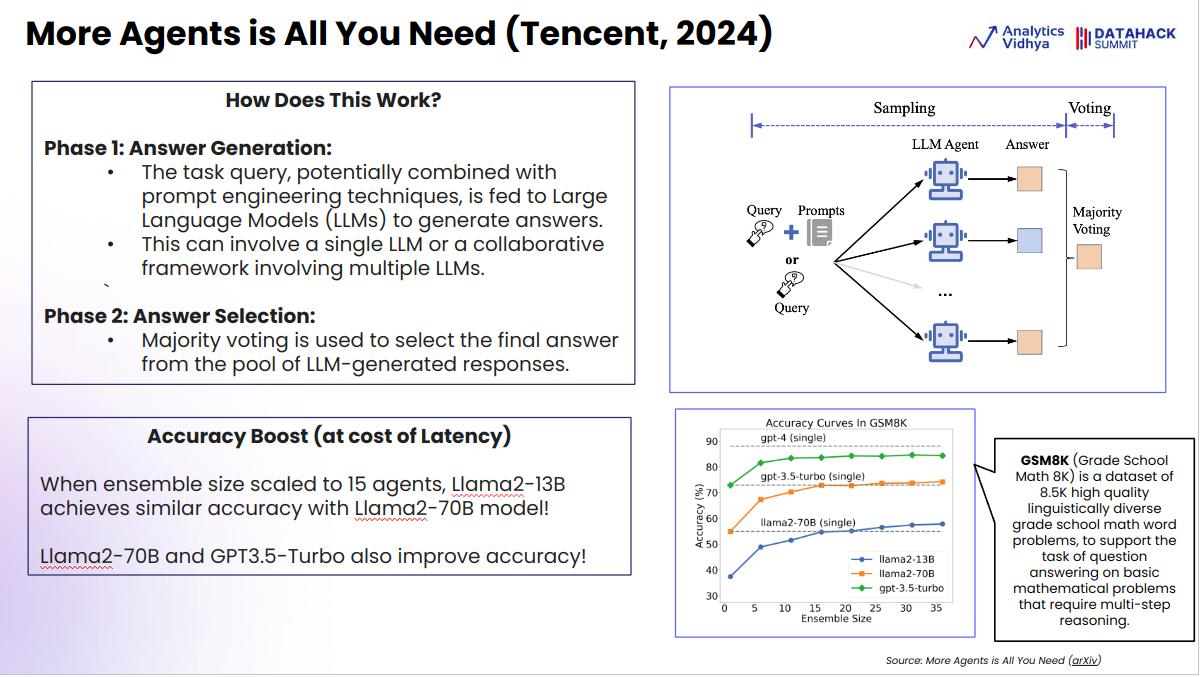
This method involves using multiple LLM agents or prompting techniques to generate multiple answers and then selecting the most common answer. This approach can help reduce hallucinations and improve overall accuracy.
Here, we discuss a research approach proposed by Tencent, emphasizing the concept of using multiple LLM (Large Language Model) agents to solve complex reasoning problems. Previous techniques, such as LLM debates and Chain of Thought (CoT) self-consistency, inspire the idea, generating multiple reasoning chains or debates among LLM agents to reach the most accurate answer.

Here’s the link: More Agents Is All You Need
In this method, multiple LLM agents are used to answer a query, and then a majority voting system is employed to determine the best answer. The rationale is that even if some responses contain hallucinations, the majority will provide consistent and reliable answers, reducing the impact of incorrect outputs.
The potential for using different LLMs in the ensemble could lead to more varied and robust results, similar to the diversity seen in random forests. The effectiveness of this approach was tested using LLaMA 2, where an ensemble size of 15 to 20 agents matched the performance of GPT-3.5 on a benchmark test. However, the approach requires significant computational resources, as it involves running multiple LLM instances and aggregating their outputs.
Hypothetical Document Embeddings (HyDE)
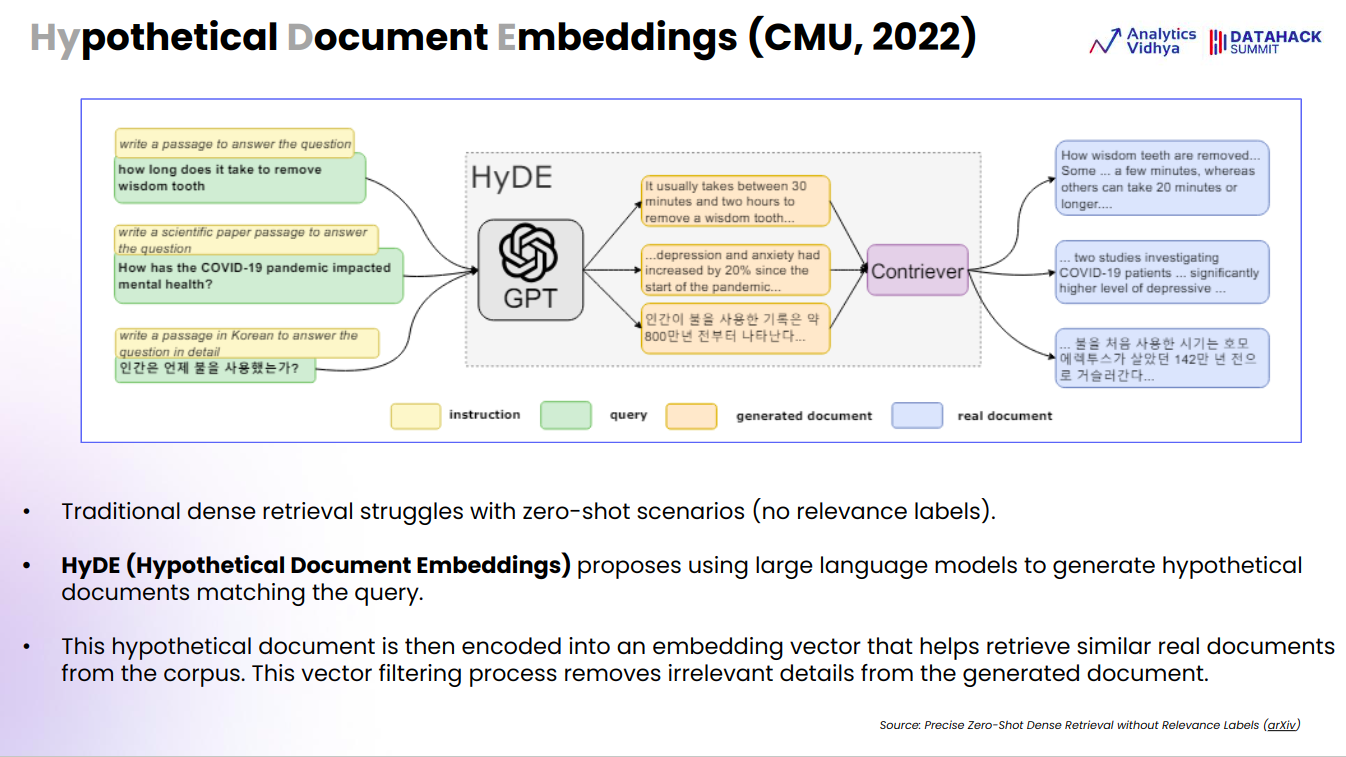
The HyDE (Hypothetical Document Embeddings) method offers a smart solution to the limitations of traditional dense retrieval systems, particularly in zero-shot scenarios where no relevant labels are available. By generating hypothetical documents through large language models, HyDE can create contextually relevant content that aligns with a query, even when prior examples or training data are lacking. This makes it well-suited for tasks that require retrieving information in unfamiliar or novel contexts.
A key strength of this approach is its ability to filter out irrelevant information from the generated hypothetical document when converting it into embedding vectors. This ensures that the retrieval system focuses on the core aspects of the query, thereby improving accuracy. Unlike traditional systems that might struggle with ambiguous or complex queries, HyDE can simulate a range of possible documents and match them to real content, which makes it more robust.
In my opinion, HyDE represents an innovative advancement in retrieval techniques by combining generative capabilities with vector-based retrieval. It leverages the creativity and flexibility of large language models to create more nuanced, contextually rich embeddings. This hybrid approach can significantly improve the retrieval of relevant documents, especially in fields like legal, academic, or technical domains, where conventional methods might fall short due to a lack of training data or relevance labels.
Reasoning Without Observation (ReWOO)
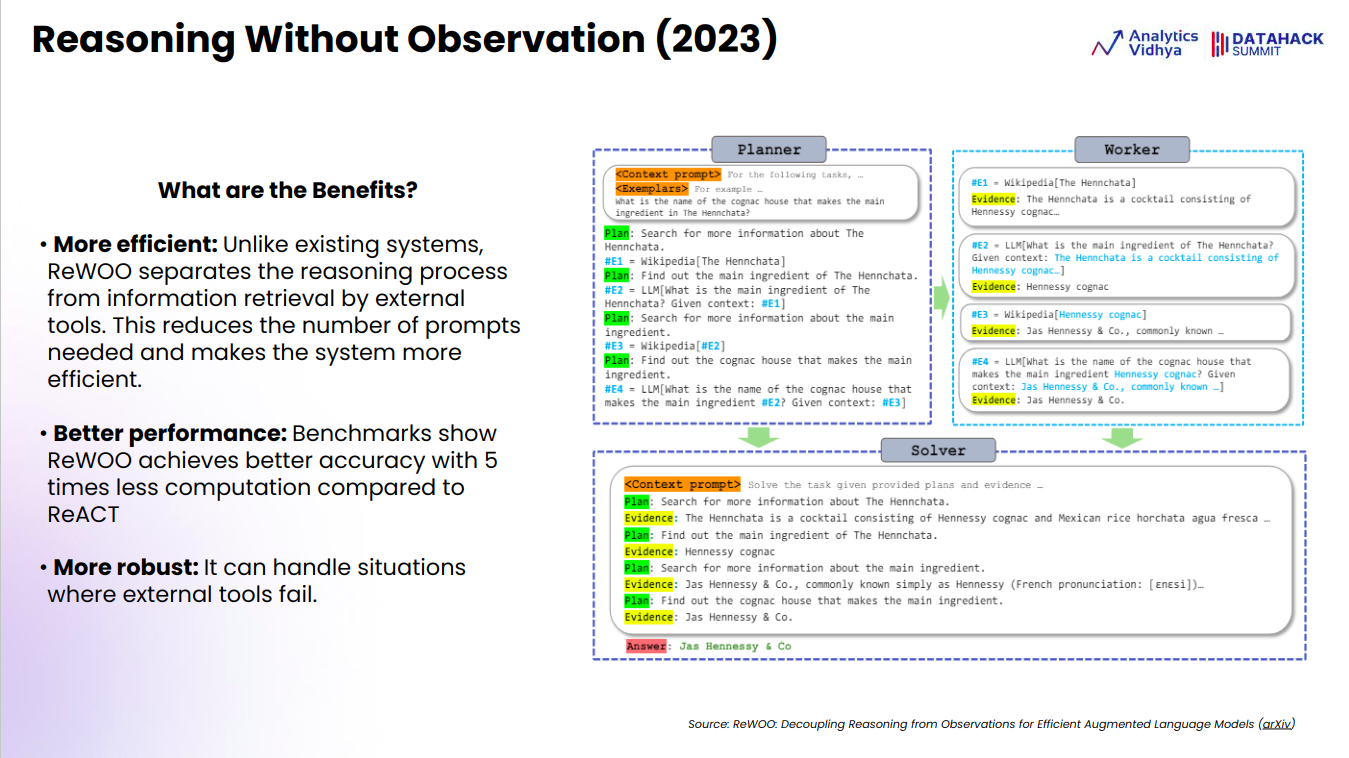
ReWOO, introduced in 2023, marks a significant advancement in AI reasoning systems. Unlike traditional approaches that intertwine reasoning with information retrieval, ReWOO efficiently separates these processes. This leads to fewer prompts, making the system more efficient and quicker.
ReWOO also demonstrates superior performance, achieving higher accuracy while requiring five times less computational power than previous models like ReACT. Another key advantage of ReWOO is its robustness; it effectively handles situations where external tools might fail, ensuring more reliable outcomes across various scenarios.
In summary, ReWOO stands out for its efficiency, enhanced performance, and resilience, offering a powerful solution for AI-driven reasoning tasks.
Running Practical Experiments Using Advanced Prompting Techniques
We’ll explore an implementation using the Discrete Reasoning over Paragraphs dataset to demonstrate the effectiveness of prompt engineering techniques.
Description of the Dataset
The dataset comprises 96,000 questions requiring multi-step reasoning based on given paragraphs. This example uses a subset of 240 annotated examples, 140 of which are for evaluation and 100 of which are for few-shot examples.
Implementation Details (Using LangChain)
The implementation uses the LangChain library and a Hugging Face API token. Key steps include:
- Setting up the environment and loading the model
- Creating prompt templates for different prompting techniques
- Implementing evaluation functions
We started by setting up the environment and moving directly to using LangChain. Here, Model ID “Mixtral” with an open-source model is used to create a tokenizer from the pre-trained model. Using the Hugging Face API, we call the language model and format the prompt. We make a prompt template where an input variable is used, and this format is used by default when prompting the language model. We use LangChain’s expression language to query and demonstrate the model with an example question about ECG (electrocardiography). Additionally, we created a function to load the embedding model.
Evaluation Metrics: Comparison of Prompting Techniques for Large Language Models
The primary metric used is accuracy, comparing the LLM’s answers to the ground truth answers in the dataset.
In the evaluation task, we restructured data from JSON into a more structured format, focusing on a dataset of 240 examples categorized into 14 types of questions. We extracted 140 examples for our evaluation. We employed a large language model (LLM) to determine the correctness of answers by prompting it to evaluate whether the LLM-generated responses were correct or incorrect.
In standard prompting, we ask the LLM to respond to user queries with concise information, providing a one-shot example and evaluating its accuracy. Using this approach, we observed an accuracy rate of 74% from 140 examples.
We modified the approach for Chain of Thought (CoT) prompting by including an additional column in our data frame for CoT reasoning. This technique involved a two-step process: first identifying relevant data and then performing the necessary reasoning to answer the question. Implementing CoT significantly improved accuracy to 90%.
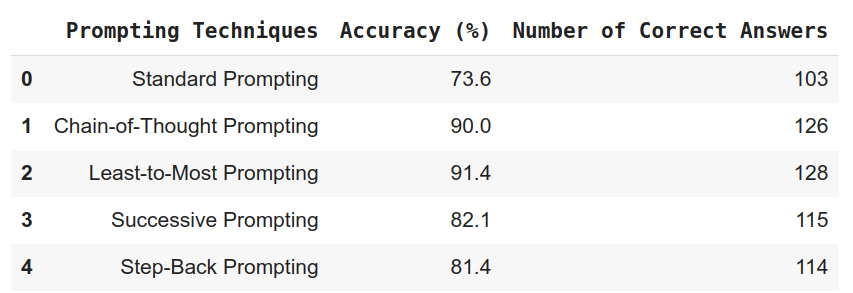
After going through all the techniques, we showcase the effectiveness of various prompting techniques by comparing their accuracy and the number of correct answers. Standard prompting, which asks a question directly, has the lowest accuracy at 73.6%, with 103 correct answers. Chain-of-Thought (CoT) prompting, which guides the model step-by-step, improves accuracy to 90.0%, with 126 correct answers. Least-to-most prompting, where simpler parts are solved first, achieves the highest accuracy at 91.4%, with 128 correct answers. Successive prompting, refining answers through multiple prompts, reaches 82.1% accuracy with 115 correct answers. Step-back prompting, asking the model to reconsider, results in 81.4% accuracy and 114 correct answers. Structured reasoning techniques like Least-to-Most and CoT outperform standard prompting, highlighting the value of guided reasoning.
For better understanding, here is the Colab notebook.
Conclusion
Prompt engineering techniques have shown significant potential in enhancing the logical reasoning capabilities of LLMs. In the example implementation, Chain of Thought prompting improved accuracy from 74% to 90%, while Least to Most Successive Prompting achieved the highest accuracy at 91.4%.
Future Research Directions
- Interleaved Retrieval with CoT Prompting: Combining information retrieval with reasoning processes for more complex, real-world applications.
- Multi-agent Approaches: Exploring the use of multiple LLM agents for debate-style reasoning and ensemble methods.
- Optimizing Prompt Generation: Developing techniques to generate the most effective prompts for specific reasoning tasks automatically.
- Addressing Hallucinations: Further research is needed to reduce hallucinations and improve the reliability of LLM reasoning outputs.
As LLMs continue to evolve, prompt engineering remains a crucial area of research and development. By refining these techniques, we can unlock LLMs’ full potential for complex reasoning tasks across various domains, bringing us closer to more robust and reliable AI systems.
If you are looking for generative AI courses online then explore – GenAI Pinnacle Program
Frequently Asked Questions
Ans. Prompt engineering involves designing effective input prompts to guide LLMs’ reasoning process. It can significantly enhance an LLM’s ability to perform complex tasks by providing structured guidance, leading to more accurate and logical outputs.
Ans. Several techniques include Chain of Thought (CoT) prompting, Least to Most Successive Prompting, Step-back Prompting, Successive Prompting, and Interleaved Retrieval with CoT Prompting.
Ans. CoT prompting significantly improves accuracy. In the example given, standard prompting achieved 74% accuracy, while CoT prompting improved this to 90% accuracy.
Ans. This technique involves breaking down complex problems into smaller sub-questions, solving them sequentially, and using the answers to build up to the final solution. It achieved the highest accuracy (91.4%) in the study mentioned.
Ans. The practical application uses the Discrete Reasoning over Paragraphs dataset. It shows how different techniques can be implemented using libraries like LangChain and evaluates their effectiveness in improving LLM performance on complex reasoning tasks.
Hi, I am Pankaj Singh Negi – Senior Content Editor | Passionate about storytelling and crafting compelling narratives that transform ideas into impactful content. I love reading about technology revolutionizing our lifestyle.