

In the era of big data and rapid technological advancement, the ability to analyze and interpret data effectively has become a cornerstone of decision-making and innovation. Python, renowned for its simplicity and versatility, has emerged as the leading programming language for data analysis. Its extensive library ecosystem enables users to seamlessly handle diverse tasks, from data manipulation and visualization to advanced statistical modeling and machine learning. This article explores the top 10 Python libraries for data analysis. Whether you’re a beginner or an experienced professional, these libraries offer scalable and efficient solutions to tackle today’s data challenges.
1. NumPy
NumPy is the foundation for numerical computing in Python. This Python library for data analysis supports large arrays and matrices and provides a collection of mathematical functions for operating on these data structures.
Advantages:
- Efficiently handles large datasets with multidimensional arrays.
- Extensive support for mathematical operations like linear algebra and Fourier transforms.
- Integration with other libraries like Pandas and SciPy.
Limitations:
- Lacks high-level data manipulation capabilities.
- Requires Pandas for working with labeled data.
import numpy as np
# Creating an array and performing operations
data = np.array([1, 2, 3, 4, 5])
print("Array:", data)
print("Mean:", np.mean(data))
print("Standard Deviation:", np.std(data))Output

2. Pandas
Pandas is a data manipulation and analysis library that introduces DataFrames for tabular data, making it easy to clean and manipulate structured datasets.
Advantages:
- Simplifies data wrangling and preprocessing.
- Offers high-level functions for merging, filtering, and grouping datasets.
- Strong integration with NumPy.
Limitations:
- Slower performance for extremely large datasets.
- Consumes significant memory for operations on big data.
import pandas as pd
# Creating a DataFrame
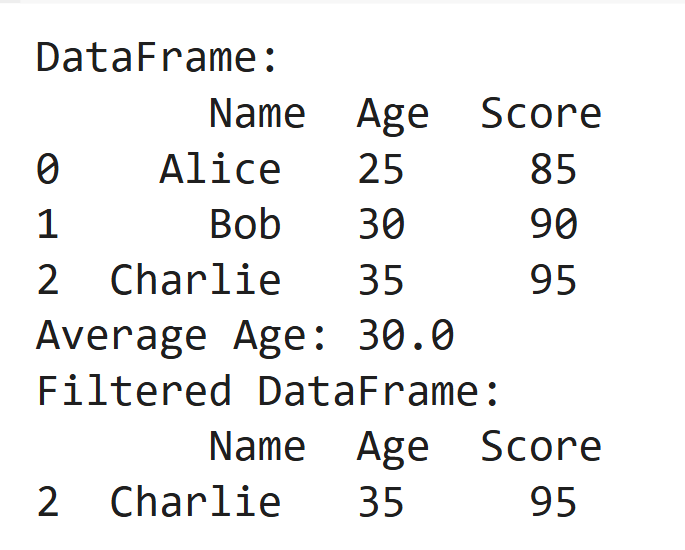
data = pd.DataFrame({'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35], 'Score': [85, 90, 95]})
print("DataFrame:\n", data)
# Data manipulation
print("Average Age:", data['Age'].mean())
print("Filtered DataFrame:\n", data[data['Score'] > 90])Output
3. Matplotlib
Matplotlib is a plotting library that enables the creation of static, interactive, and animated visualizations.
Advantages:
- Highly customizable visualizations.
- Serves as the base for libraries like Seaborn and Pandas plotting.
- Wide range of plot types (line, scatter, bar, etc.).
Limitations:
- Complex syntax for advanced visualizations.
- Limited aesthetic appeal compared to modern libraries.
import matplotlib.pyplot as plt
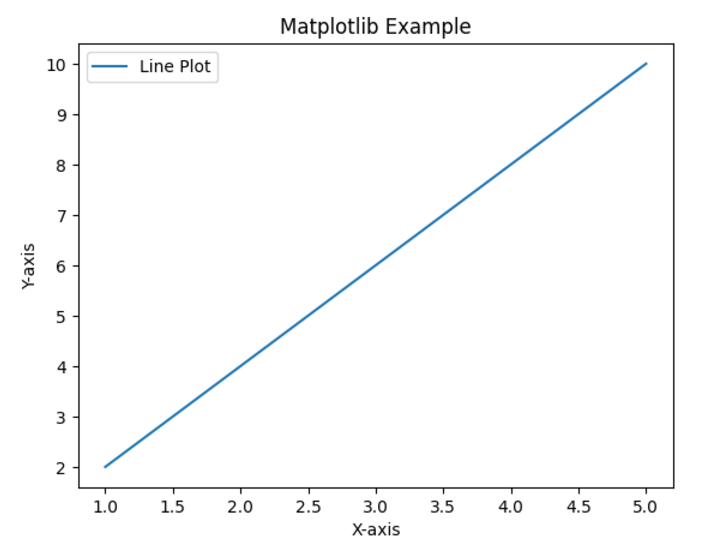
# Data for plotting
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# Plotting
plt.plot(x, y, label="Line Plot")
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Matplotlib Example')
plt.legend()
plt.show()Output
4. Seaborn
Seaborn, Python library for data analysis, is built on Matplotlib and simplifies the creation of statistical visualizations with a focus on attractive aesthetics.
Advantages:
- Easy-to-create, aesthetically pleasing plots.
- Built-in themes and color palettes for enhanced visuals.
- Simplifies statistical plots like heatmaps and pair plots.
Limitations:
- Relies on Matplotlib for backend functionality.
- Limited customization compared to Matplotlib.
import seaborn as sns
import matplotlib.pyplot as plt
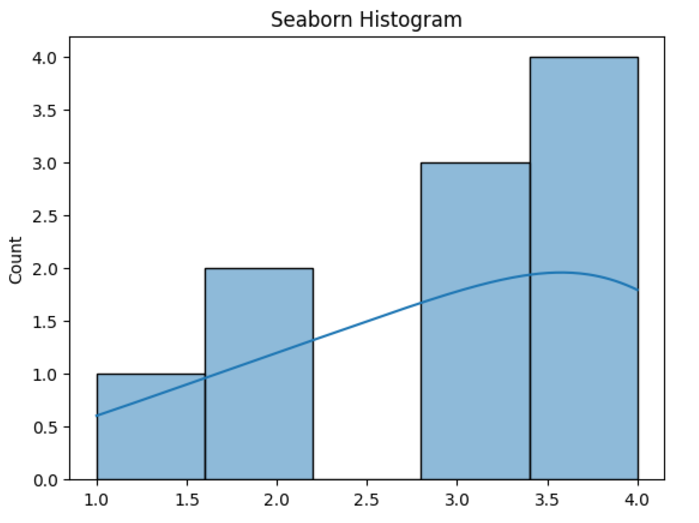
# Sample data
data = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]
# Plotting a histogram
sns.histplot(data, kde=True)
plt.title('Seaborn Histogram')
plt.show()Output
5. SciPy
SciPy builds on NumPy to provide tools for scientific computing, including modules for optimization, integration, and signal processing.
Advantages:
- Comprehensive library for scientific tasks.
- Extensive documentation and examples.
- Integrates well with NumPy and Pandas.
Limitations:
- Requires familiarity with scientific computations.
- Not suitable for high-level data manipulation tasks.
from scipy.stats import ttest_ind
# Sample data
group1 = [1, 2, 3, 4, 5]
group2 = [2, 3, 4, 5, 6]
# T-test
t_stat, p_value = ttest_ind(group1, group2)
print("T-Statistic:", t_stat)
print("P-Value:", p_value)Output

6. Scikit-learn
Scikit-learn is a machine learning library, offering classification, regression, clustering, and more tools.
Advantages:
- User-friendly API with well-documented functions.
- Wide variety of prebuilt machine learning models.
- Strong integration with Pandas and NumPy.
Limitations:
- Limited support for deep learning.
- Not designed for large-scale distributed training.
from sklearn.linear_model import LinearRegression
# Data
X = [[1], [2], [3], [4]] # Features
y = [2, 4, 6, 8] # Target
# Model
model = LinearRegression()
model.fit(X, y)
print("Prediction for X=5:", model.predict([[5]])[0])Output
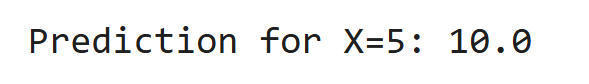
7. Statsmodels
Statsmodels, Python library for data analysis, provides tools for statistical modeling and hypothesis testing, including linear models and time series analysis.
Advantages:
- Ideal for econometrics and statistical research.
- Detailed output for statistical tests and models.
- Strong focus on hypothesis testing.
Limitations:
- Steeper learning curve for beginners.
- Slower compared to Scikit-learn for predictive modeling.
import statsmodels.api as sm
# Data
X = [1, 2, 3, 4]
y = [2, 4, 6, 8]
X = sm.add_constant(X) # Add constant for intercept
# Model
model = sm.OLS(y, X).fit()
print(model.summary())Output

8. Plotly
Plotly is an interactive plotting library used for creating web-based dashboards and visualizations.
Advantages:
- Highly interactive and responsive visuals.
- Easy integration with web applications.
- Supports 3D and advanced charts.
Limitations:
- Heavier on browser memory for large datasets.
- May require additional configuration for deployment.
import plotly.express as px
# Sample data
data = px.data.iris()
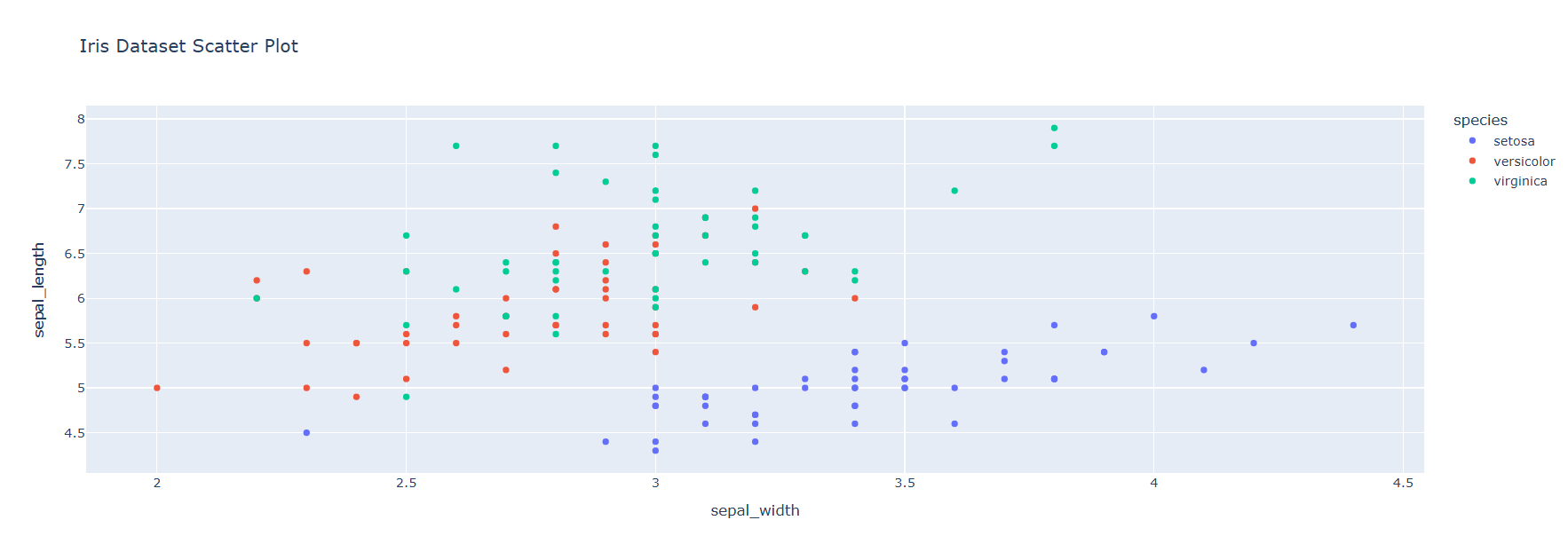
# Scatter plot
fig = px.scatter(data, x="sepal_width", y="sepal_length", color="species", title="Iris Dataset Scatter Plot")
fig.show()Output
9. PySpark
PySpark is the Python API for Apache Spark, enabling large-scale data processing and distributed computing.
Advantages:
- Handles big data efficiently.
- Integrates well with Hadoop and other big data tools.
- Supports machine learning with MLlib.
Limitations:
- Requires a Spark environment to run.
- Steeper learning curve for beginners.
!pip install pyspark
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName("PySpark Example").getOrCreate()
# Create a DataFrame
data = spark.createDataFrame([(1, "Alice"), (2, "Bob")], ["ID", "Name"])
data.show()Output

10. Altair
Altair is a declarative statistical visualization library based on Vega and Vega-Lite.
Advantages:
- Simple syntax for creating complex visualizations.
- Integration with Pandas for seamless data plotting.
Limitations:
- Limited interactivity compared to Plotly.
- Cannot handle extremely large datasets directly.
import altair as alt
import pandas as pd
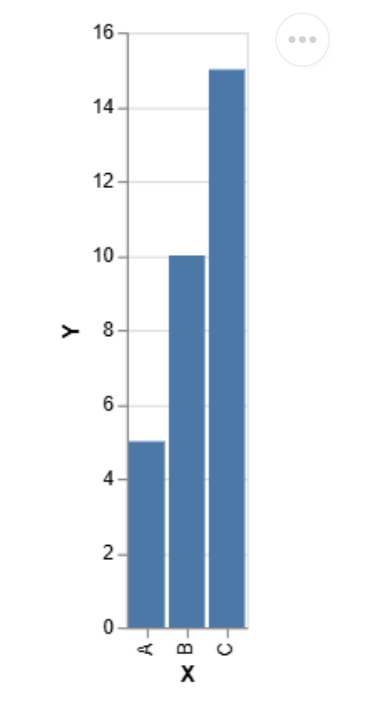
# Simple bar chart
data = pd.DataFrame({'X': ['A', 'B', 'C'], 'Y': [5, 10, 15]})
chart = alt.Chart(data).mark_bar().encode(x='X', y='Y')
chart.display() Output
How to Choose the Right Python Library for Data Analysis?
Understand the Nature of Your Task
The first step in selecting a Python library for data analysis is understanding the specific requirements of your task. Pandas and NumPy are excellent data cleaning and manipulation choices, offering powerful tools to handle structured datasets. Matplotlib provides basic plotting capabilities for data visualisation, while Seaborn creates visually appealing statistical charts. If interactive visualizations are needed, library like Plotly are ideal. When it comes to statistical analysis, Statsmodels excels in hypothesis testing, and SciPy is well-suited for performing advanced mathematical operations.
Consider Dataset Size
The size of your dataset can influence the choice of libraries. Pandas and NumPy operate efficiently for small to medium-sized datasets. However, when dealing with large datasets or distributed systems, tools like PySpark are better options. These Python libraries are designed to process data across multiple nodes, making them ideal for big data environments.
Define Your Analysis Objectives
Your analysis goals also guide the library selection. For Exploratory Data Analysis (EDA), Pandas is a go-to for data inspection, and Seaborn is useful for generating visual insights. For predictive modeling, Scikit-learn offers an extensive toolkit for preprocessing and implementing machine learning algorithms. If your focus is on statistical modeling, Statsmodels shines with features like regression analysis and time series forecasting.
Prioritize Usability and Learning Curve
Libraries vary in usability and complexity. Beginners should start with user-friendly libraries like Pandas and Matplotlib, supported by extensive documentation and examples. Advanced users can explore more complex tools like SciPy, Scikit-learn, and PySpark, which are suitable for high-level tasks but may require a deeper understanding.
Integration and Compatibility
Lastly, ensure the library integrates seamlessly with your existing tools or platforms. For instance, Matplotlib works exceptionally well within Jupyter Notebooks, a popular environment for data analysis. Similarly, PySpark is designed for compatibility with Apache Spark, making it ideal for distributed computing tasks. Choosing libraries that align with your workflow will streamline the analysis process.
Why Python for Data Analysis?
Python’s dominance in data analysis stems from several key advantages:
- Ease of Use: Its intuitive syntax lowers the learning curve for newcomers while providing advanced functionality for experienced users. Python allows analysts to write clear and concise code, speeding up problem-solving and data exploration.
- Extensive Libraries: Python boasts a rich library ecosystem designed for data manipulation, statistical analysis, and visualization.
- Community Support: Python’s vast, active community contributes continuous updates, tutorials, and solutions, ensuring robust support for users at all levels.
- Integration with Big Data Tools: Python seamlessly integrates with big data technologies like Hadoop, Spark, and AWS, making it a top choice for handling large datasets in distributed systems.
Conclusion
Python’s vast and diverse library ecosystem makes it a powerhouse for data analysis, capable of addressing tasks ranging from data cleaning and transformation to advanced statistical modeling and visualization. Whether you’re a beginner exploring foundational libraries like NumPy, Pandas, and Matplotlib, or an advanced user leveraging the capabilities of Scikit-learn, PySpark, or Plotly, Python offers tools tailored to every stage of the data workflow.
Choosing the right library hinges on understanding your task, dataset size, and analysis objectives while considering usability and integration with your existing environment. With Python, the possibilities for extracting actionable insights from data are nearly limitless, solidifying its status as an essential tool in today’s data-driven world.
A 23-year-old, pursuing her Master’s in English, an avid reader, and a melophile. My all-time favorite quote is by Albus Dumbledore – “Happiness can be found even in the darkest of times if one remembers to turn on the light.”